

A proposal for storing small balances in snapshots
In order to keep storage requirements on nodes low, regular snapshots are a must. In the near future, these snapshots are created without shutting down the COO, decentralized and independently of each other. With sizes of currently about 30–40 MB (uncompressed, September snapshot) it isn’t a problem to quickly verify them. But what if snapshots would bloat up into the two-digit Gigabytes?
The 1i problem
While regular spam and data transactions are no problem for a snapshot, an attacker could gather a few Mi and split them on millions of addresses, with 1i each. If we adjusted the snapshot format to be more storage efficient, we would still need ~50 bytes per address/value pair, which makes around 48 Megabytes per million addresses. With an FPGA, creating this many balances only takes 2 days (assuming 6 TPS) and does not consume a lot of energy. If an attacker would buy multiple of those FPGAs and constantly carry out this attack, he could get the snapshot size into the gigabytes while maintaining a pretty low cost. If he uses reusable addresses, this gets even worse, as we have to save the address AND an additional public key in a snapshot.
This problem isn’t new in the world of cryptocurrencies. Sending bitcoins results in the so-called “Unspent Transaction Outputs” (UTXO). To spend bitcoins, you need to reference an UTXO and sign it with the correct private key, removing the old UTXO, but creating new ones in return (on other words, you reference the output where you received your coins and use your private key to prove they are yours). As an address can have multiple UTXOs (if you received multiple times), the number of them is constantly near 50 million:
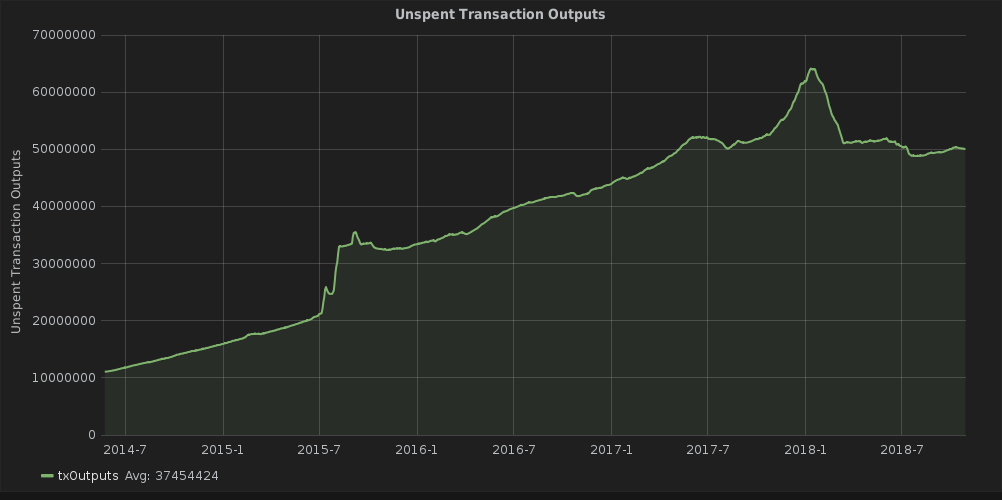
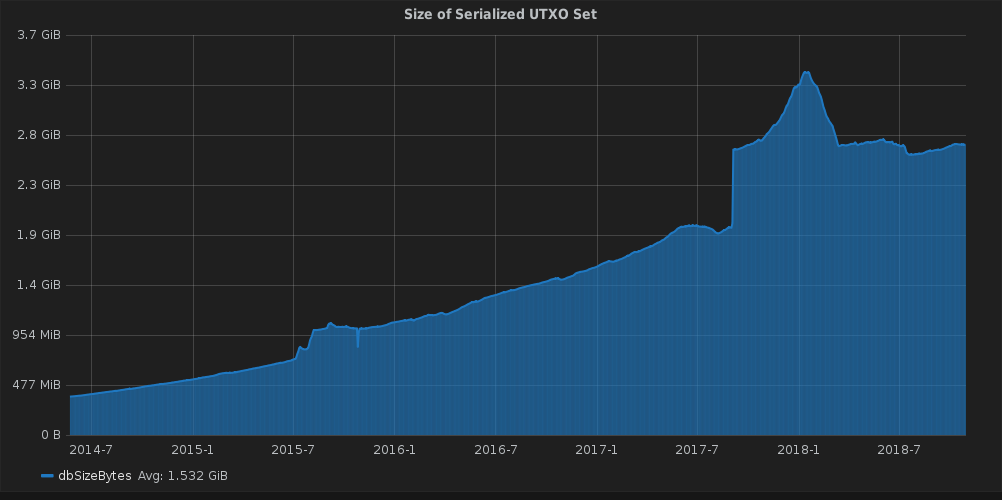
A snapshot of Bitcoin would therefore require almost 3 GB. It also doesn’t look much better for Ethereum (45M unique accounts; https://etherscan.io/chart/address), where you can’t even prune empty addresses. IOTA does have around 400.000 addresses with balance at the moment, but in the future of IOT, this is subject to increase into the billions of addresses, mostly with small balances. In the latest snapshot, over 4% only had a single digit value on them (almost half of them exact 1 IOTA), 12,9% were at 1Ki or below. Setting up a minimum balance per address to save storage, similar to how Ripple handles it, would however completely defeat the purpose of micropayments. So we have to save node space in a different way.
Most of the snapshot space is used to store the public key (~48 bytes in a more efficient format for IOTA, ~32 for a shorter bitcoin address), so this is the part where most storage can be saved.
Solution 1: Only store a part of the pubkey
Couldn’t someone simply collect all micropayments if we decreased security by a lot?

Theoretically, yes, in practice, no. Let me show you an example why micropayments are in general unattractive to steal.
Image, Alice has a safe protected by a 4-pin-code at home with 1,000$ in cash in it. Alice is on vacation, so evil Bob has all the time he needs to crack the safe. As the safe only allows 10 attempts per minute, Bob would have to try on average for just about 8 hours to crack it. Perhaps he is lucky and finds it after just 3 hours, or unlucky and it takes him over 16 hours. In any case, spending a whole day and earn 1,000$ for it, would be totally worth it.
If the safe now only contained 100$, Bob could still go for it. But if he doesn’t find the right code right away, he might have gotten more if he was at work for the time he attempted cracking the safe.
If we now reduce the content to a single dollar, Bob surely has better things to do. In this case, Alice could even tell Bob the first number, but Bob still has no incentive to crack the safe, despite he would likely manage it within one hour now.
What does this mean for IOTA
Stealing almost any cryptocurrency is quite similar to cracking such a safe. The limit of attempts you can perform per second is decided by your hardware. The amount of lock-digits is decided by the cryptographic hash function (IOTA would resemble 116-digit lock). As attempting to steal funds requires electricity, hardware and time, we only have to ensure that these costs are a few thousand times higher than the value of the crypto you could steal. In other words, the lower the amount on an address, the lower we can put the security. Any attacker, even with free electricity and hardware, would rather use it to e.g mine Monero instead of wasting it, just as Bob would simply look for a more rewarding job.
As most microtransactions will use security level 1, only saving the first 27 trytes of an address will not degrade the security too much, as randomly finding a seed that hashes to the given shorted address is just as difficult as brute-forcing a double spend. In fact, there are still over 4,4*10³⁸ possible combinations. While I’m unaware of how fast today’s hardware is in matters of finding an address starting with the same 27 trytes, no one would try it if the address only contains a fraction of a dollar.
We could decrease that even more, but at around 11–13 trytes an attacker with several terrahashes has a good chance to crack the address in a reasonable time. As hardware keeps getting more efficient, this defines a bottom to how low we can put the security before risking a steal.
This method already allows a reasonable save and decreases the storage requirement by a significant factor. Nano-balances can simply be degraded in security over the time until it is worth to steal them, creating an incentive to remove tiny balances in a reasonable time. This also decreases the amount of addresses with balance. In fact, over 2,5% of addresses only contain a single iota, which would be pruned in time
Solution 2: Distributed saving
To prevent prefix-attacks on reusable addresses each node needs to store a different value making it impossible to find a seed with an address approved by a lot of nodes. Therefore each node only saves T random trits from the address. Which ones and in which order is decided by a node-seed.
