

Qubic Lite Explained — an Introduction to Relative Consensus and IAM Streams
After the launch of the first Qubic Lite prototype last week on qubiota.com, it is about time to finally publish the source code, which will happen this sunday. To prepare for that, I figured it was best to write a short yet simple technical article disclosing the very basic concepts needed to understand the data layer and consensus mechanism utilized by Qlite.
Part I: Consensus is Relative
A qubic is processed by several q-nodes acting as oracles. The power of the qubic lies in the consensus: you do not have to trust any single oracle, instead you put your trust into the entirety of the oracle cluster, called “assembly”. A certain amount of malicious or unreliable actors can be tolerated (up to 33% without any effect at all; up to 67% without your qubic releasing wrong results).
In fact, you should always expect some bad actors. And this gives rise to the first problem we have to consider when designing a Qubic implementation:
If we cannot trust any single oracle, who publishes the qubic results into the consensus stream?
And the answer is actually quite simple: There cannot be such a consensus stream acting as single source of truth since that would defeat the entire purpose of everything that aims to be decentralized. But let’s make this a little bit more tangible:
A Short Illustration
Imagine walking around the streets. Suddenly your old friend Bob stops you and tells you some gossip about Alice. “Well, good to know”, you might think,- but would you bet your life savings on the truth of what he just told you? Certainly not quite yet. If you want to be really sure, you go around and ask more people. And as you do so, you will naturally realize that truth is relative, because it depends on who you ask. But the more people you ask, the more information you gather to make an educated guess.
Similar to this, there is no single data stream publishing the consensus results of the qubic. Instead, every individual oracle maintains its own data stream. If you want to find out the result for a qubic at a certain epoch, you have to check the claims of a statistically significant portion of the assembly at that specific epoch yourself. You do not just read a pre-built consensus result but you reproduce the consensus yourself.

In other words: There is no absolute global consensus. You do not go around the city and tell everyone that you have done your research and from here on the truth shall be that the gossip about Alice is indeed true. People might consider your opinion yet they will still keep listening to other sources. Defining the truth is not in your power. Consensus is reached locally: When your qubic utilizes the results published in past epochs, every oracle individually recreates the consensus that was reached back then.
Example
Let’s say you have a qubic that always takes the result from the previous epoch and doubles it to calculate the new result for the next epoch.
90% of the oracles in your assembly might find that the result from the previous epoch #7 was “64”, while the remaining 10% think that no quorum was reached (maybe they do not see a certain transaction on the tangle). So now we already have a staggering 90% of nodes publishing “128” in epoch #8 while only 10% publish NULL (or anything else indicating that that no quorum was reached)
During epoch #9, however, many more nodes will think that a quorum of at least 67% has been reached during epoch #8 and only very few would be convinced otherwise (it requires quite some bad luck to mistake 90% for <67%). It might be something as high as 98% now². This way uncertainty will be washed out statistically over time, the true power of relative consensus.
This procedure is not limited to the oracles processing the qubic, but has to be performed by everyone who wants to read any epoch result in order to not rely on a single source of truth. Fully realizing that there is no “absolute consensus” and that the consensus always depends on the observer is the first step to understanding this protocol.
Part II: Introducing IAM Streams
So now that we have gotten a clearer picture of what consensus really means in regards to Qlite, we can talk about the technical implementation of the messaging layer where oracles can publish their claims in an authenticated fashion. This layer is located between the core IOTA protocol and Qubic Lite. It utilizes the data integrity of the tangle and provides Qlite with additional features required to find data efficiently.
Why MAM is Not the Best Choice here

MAM (“masked authenticated messaging”) is such a messaging layer. It allows for masked data streams, meaning that the data can be protected from unauthorized readers. The messages in the stream are linked to a chain. So if you can read one message, you can find out where to look for the next one. However, Qubic requires you to efficiently jump to any position (= qubic epoch) in the oracle streams in order to determine the result of that epoch:
Imagine you want to find out what a certain oracle said in epoch #20,000. If it published its claims in MAM streams, you would have to traverse through all 19,999 claims before that in order to find claim #20,000. Let n be the epoch, your efficiency will be O(n). With a workaround¹ you could increase that to logarithmic efficiency: O(log n).
The Idea for IAM
However, why go for logarithmic if you can actually find the epoch with a constant effort O(1) which is equally low for every epoch, be it #5 or #500,000,000? The trick is to design a messaging layer that works based on indexes: every statement can be directly found by its index. This is the idea behind IAM: “Indexed Authenticated Messaging”.
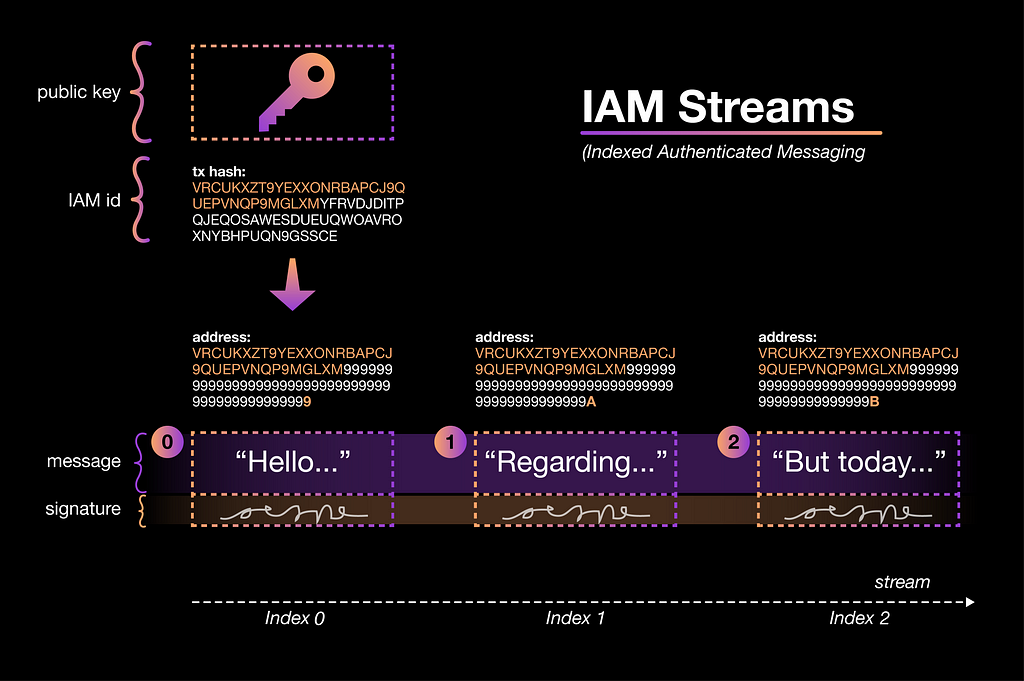
IAM Stream Structure
An IAM stream consists of:
- a single root transaction containing the public key of the stream
- signed messages attached to any indexes in the stream
The “IAM identity” (transaction hash of the root transaction) is really all that is needed to read from the stream. Firstly, the tangle address for any index is deterministically derived from it. Secondly, it directly links the reader to the public key needed to verify the authenticity of any message in the stream.
Deriving an Index Address from the IAM Identity
Building the address of the stream at a certain index is pretty simple. Just like any other transaction hash, the IAM identity has a length of 81 trytes. Keep the first 30 trytes³ and replace the rest with the tryte encoded index. To encode the index, you simply convert it from base 10 [0–9] to base 27 [9,A-Z]. (examples: 0→9; 1→A; 27→A9; 19683→A999) and fill it up from the left with 9’s to a length of 51 (51+30=81). Example:
TASK) Build address for index 42 (→AO) of IAM identity: NEBOJBNVLLDZCXNZJSBPOULEDLJWZVPCHEKTDKVKPFBXKDHFYIDMHQEFOZMLWH9WBPNLCMKXMFYIXPRPVMK9GXOUK9
RESULT) Index Address: NEBOJBNVLLDZCXNZJSBPOULEDLJWZV9999999999999999999999999999999999999999999999999AO
Writing a Message to the Stream
To write a message to the channel at that index, you simply attach a signature to your message and send the data package to the index address. Now it’s very easy for a reader to find and authenticate your transaction. You can send messages of any length by chaining multiple transactions together.
Closing Words
Relative consensus and IAM streams are certainly among the most important design choices defining Qlite. Both working together hand in hand is the very foundation for this protocol. The Qubic Lite library (which will be released this sunday) has fully implemented them already. If you have any questions, I’m happy to answer them on discord (microhash#4229).
Credits:
Many thanks once again to Qyvxz for providing these amazing info graphics. Here is his donation address in case you like them and want to honor him for his work:
UNMYNQBRBLG9WPBEUCXAKJLYWDHYMICUDTKGAOHPYMNGWFOOSBRZ99OJT9ZFFXAWIQAOFKYSLIQYBCDDDAHQYQDUAC
Footnotes:
¹ … Each oracle could maintain a meta list of addresses in a new MAM stream. For example, that list could contain the address of every 25th message. So if you are looking for message #1,043, you could find the address for index #1,025 much faster and then start to traverse from there instead of traversing all the way from #0. If that list becomes too long, you can still create a meta meta list and so on. This is however less efficient and much more maintaining is necessary that can be avoided by using IAM streams insteads.
² … 98% is just an arbitrary number to illustrate the process. It’s impossible to determine the exact figure without having much more details available.
³ … Other lengths could be chosen. 30 trytes provides sufficient security and the left 51 trytes leave enough space for more complex indexes, possibly containing whole character sequences instead of just plain integer positions.
