

The Trust Machine – Part 3: Quadruple entry accounting
The Trust Machine — Part3: Quadruple entry accounting
Designing humanities trust layer for the digital world
In the last two parts of this series of blog posts, we discussed fundamental facts about DLTs and introduced the idea to use real world trust as a sybil-protection mechanism.
In this part we are going to get a little bit more technical and discuss one of the key innovations of IOTA — the quadruple entry accounting (formerly known as the parallel reality based ledger state) — which forms the basis for IOTAs unique ledger.
The history of accounting
To understand the design decisions behind this form of accounting, we are going to discuss the different forms of accounting used throughout human history in chronological order.
Single entry accounting
The history of accounting starts tens of thousands of years ago in early Mesopotamia. Advances in reading, writing and mathematics gave rise to the first accounting system — the single entry accounting.
It is a very simple form of ledger that most people are familiar with and it usually consists out of a list of entries with 3 columns. Increases of the balance are usually shown in black and decreases are shown in red (with parenthesis):
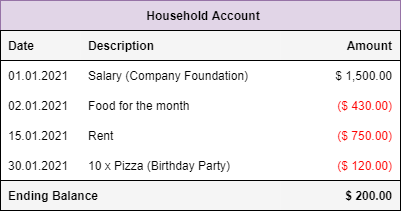
This ledger is very easy to understand and we are still using this form of accounting today (e.g. for small businesses or keeping track of the expenses of a household).
It’s biggest problem is that it is very hard to audit or generate reports. Imagine trying to answer the Question of: “How much money was spent on rent?”.
The only way to answer this question would be to go through every single entry in the ledger and sum up the corresponding values if they fit a certain category (which is a very inefficient and tiresome process — especially for large ledgers).
Double entry accounting
As societies became more complex, the economic activities performed by humans also got more complex and the need for a different and more efficient accounting system arose.
In 1494 an Italian monk named Luca Pacioli released a manuscript in which he describes a new form of accounting — the double entry accounting.
It works very similar to the single entry accounting but instead of maintaining just a single account that represents e.g. an entities cash holdings, it maintains several different accounts that are separated according to their topic and/or belonging to a certain identity.
Note: The collection of accounts related to an economic entity is called a book and the act of maintaining these accounts is called book keeping.

Whenever we create an entry in our cash account, we also create a corresponding but inverted entry in another account. After all, every increase in our cash account corresponds to a decrease in somebody else’s cash account (and vice versa).
Looking at the different accounts, it becomes very easy to answer all kinds of questions regarding the operational status of an organization, but it also becomes easier to audit the validity of i.e. reported tax numbers (since the books of different organizations need to have matching numbers).
This massively boosted transparency and reduced fraud and corruption which allowed for even bigger economic actors to arise.
Triple entry accounting
While the double entry accounting improved the audibility of economic actors, everybody was still maintaining their own separate books and auditing them was a manual and tiresome process that was often prone to errors and mistakes.
Distributed ledger technology now introduces a third entry — the transaction (which was shown as a dashed line in the previous image) — and persist it on a public and tamper proof ledger. It contains the instructions how to modify the ledger state. Nodes taking part in a decentralized ledger agree to a starting state (the genesis) and then simply apply the same transactions to arrive at the same result.
For the first time in human history we were able to have a completely open and secure way of collectively maintaining a shared ledger, giving rise to electronic cash and programmable money.
While the ideas of the tripple entry accounting are inspired by the double entry accounting where every transaction modifies the balances on two sides (sender and receiver), it uses a slightly different terminology which aims at generalizing the concepts discussed before.
Instead of tracking balances associated to different accounts (which were only necessary to make the ledger easier to read for humans), the ledger tracks balances individually. Whenever a balance gets spent by a transaction, it is marked as spent and new balances are created that are the result of the corresponding transaction.
Balances can only be spent in total and every transaction has to create new balances according to a certain smart contract (e.g. create exactly the same amount of funds as were consumed). Transactions can accordingly be seen as small programs that use existing balances as inputs to create new balances as outputs.
One way to model this, is as a DAG where the transactions are the edges that connect all outputs that have ever existed.

The ability to spend an output is usually tied to some condition (i.e. proving access to the private key of a cryptographic address) and the set of unspent outputs at the tip of this DAG is considered to be the current ledger state.
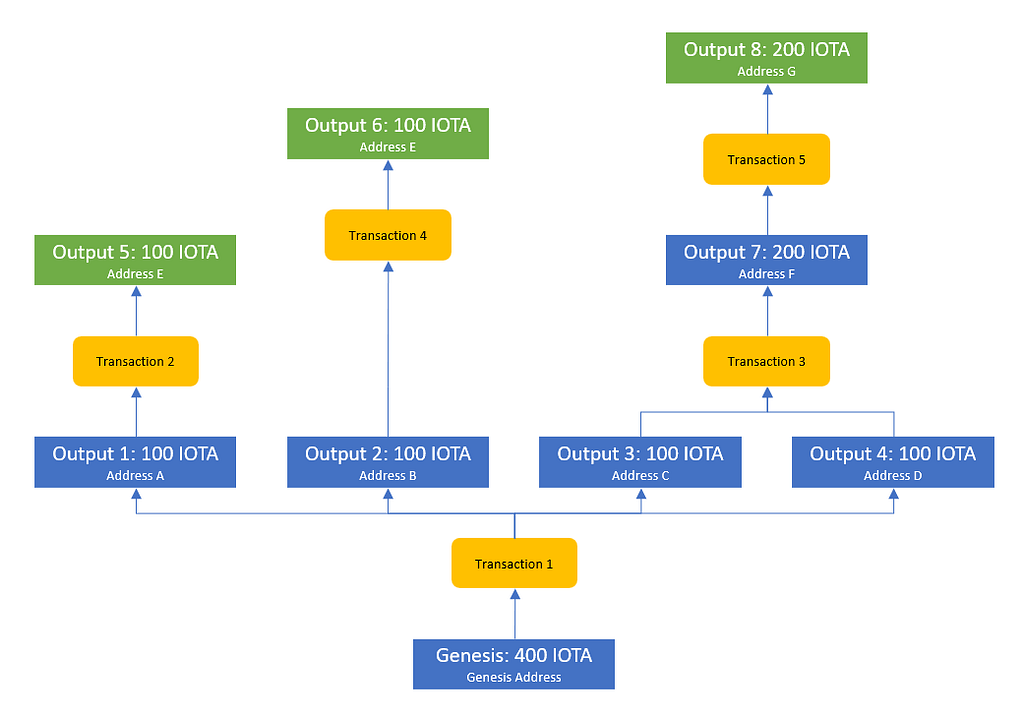
This model is called the UTXO (unspent transaction output) model and it represents one of the key innovations of Satoshi Nakamoto.
Total order in the UTXO model
A fascinating aspect of this form of ledger state is that it does not rely on a total order of events to validate transactions and applying the same transactions will lead to exactly the same ledger state, no matter in which order the transactions arrive.
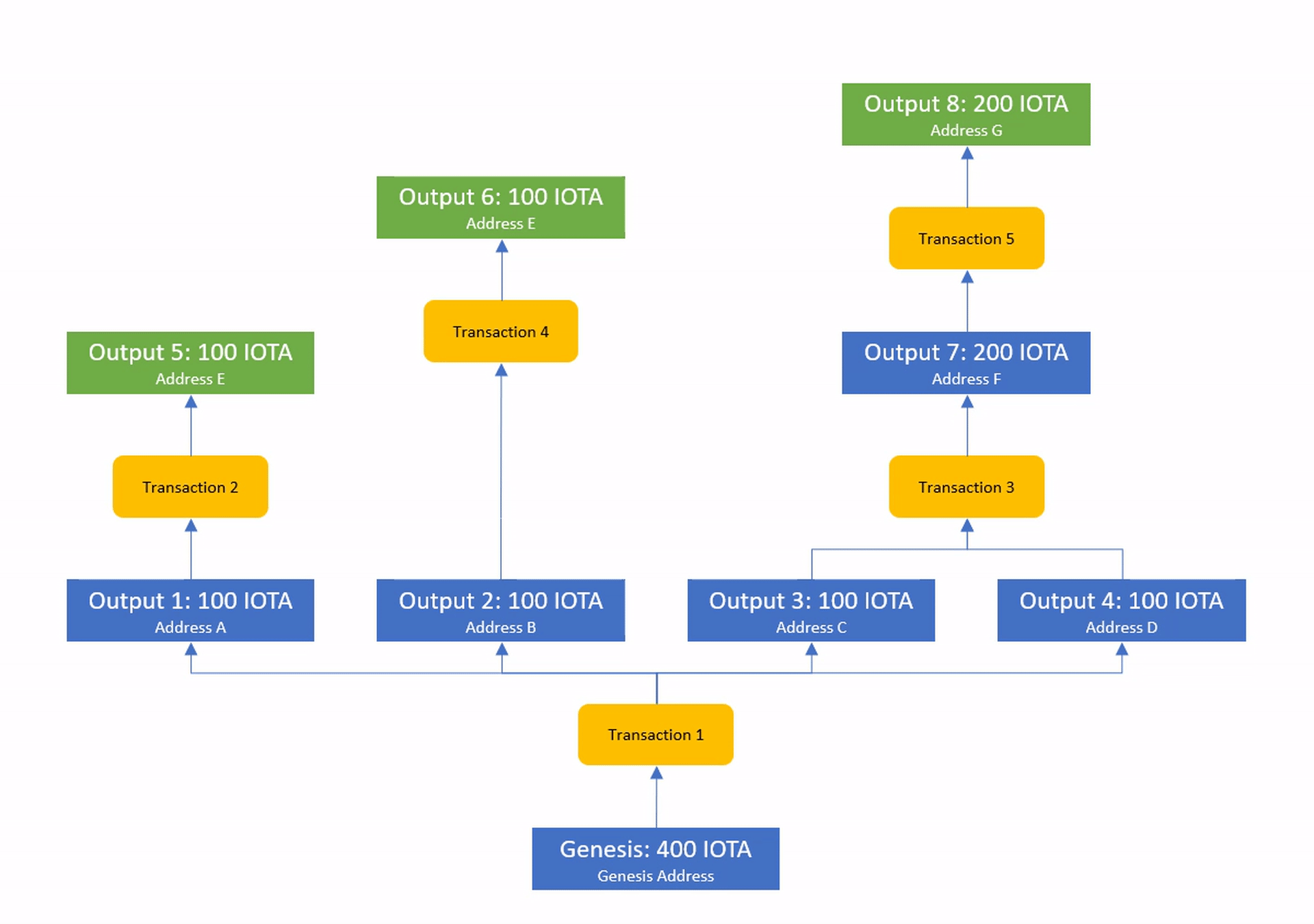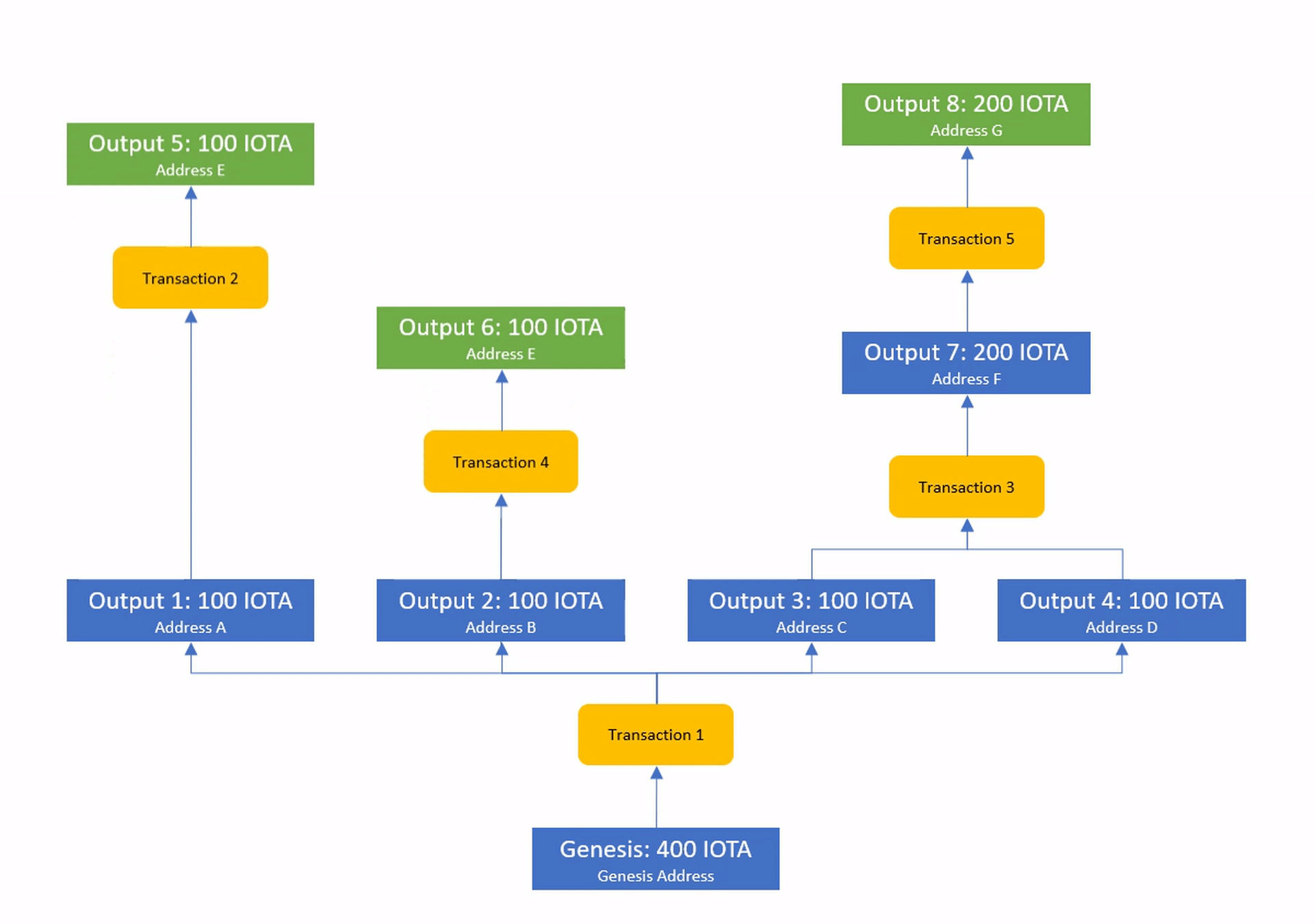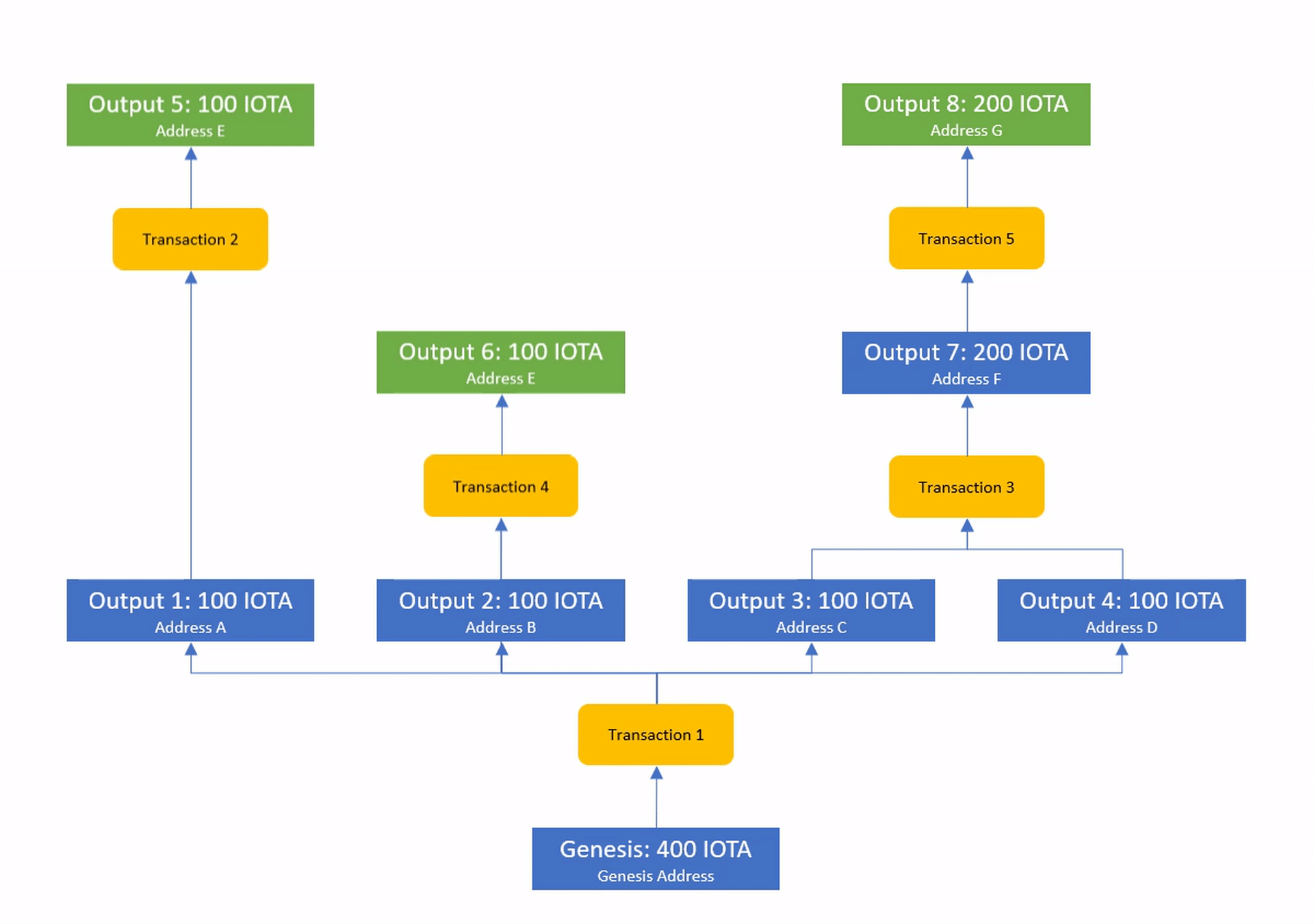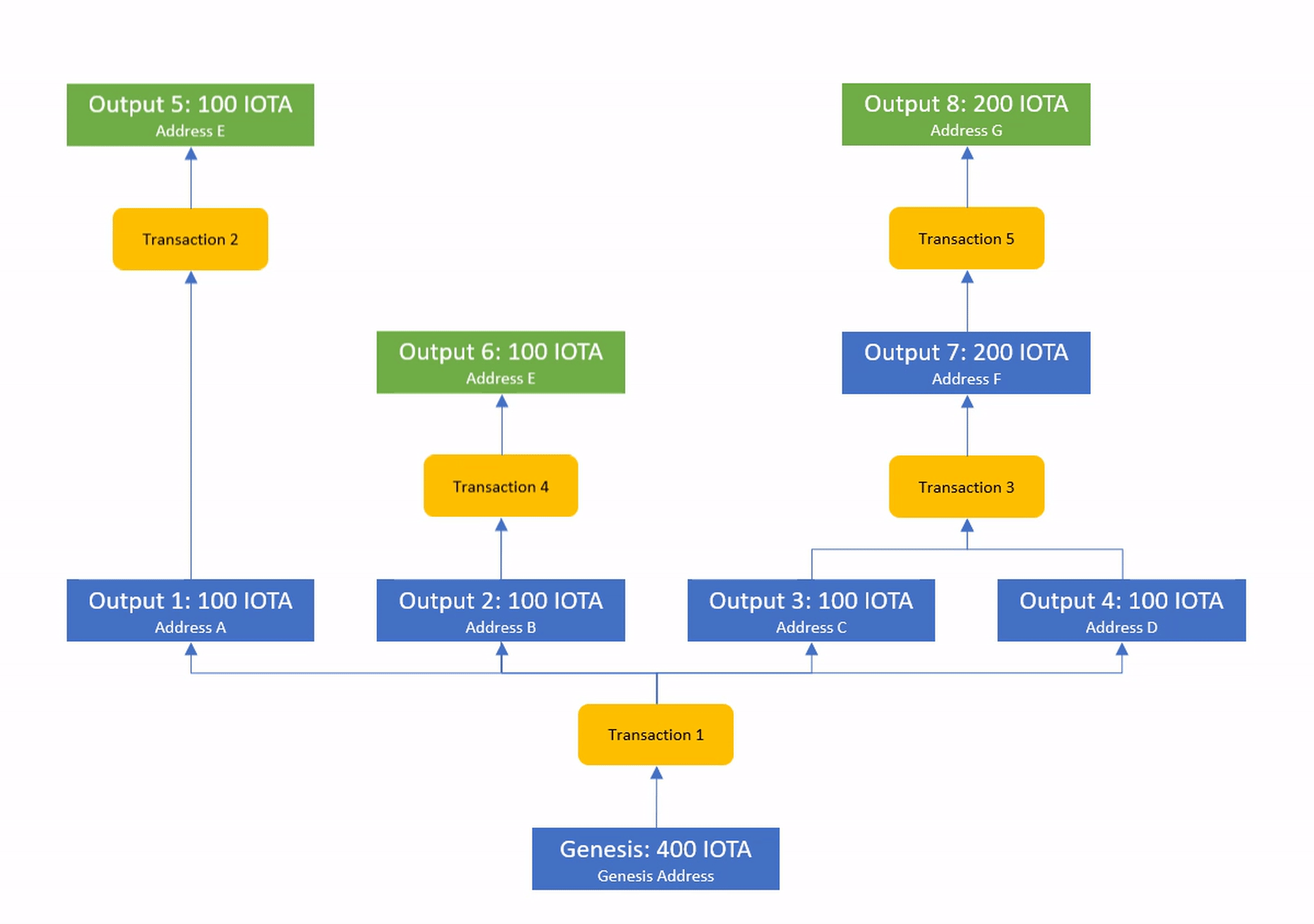
Even nodes that see dependent transactions completely out of order will still be able to arrive at the same ledger state if they simply wait with the execution until all inputs of each transaction have become known.
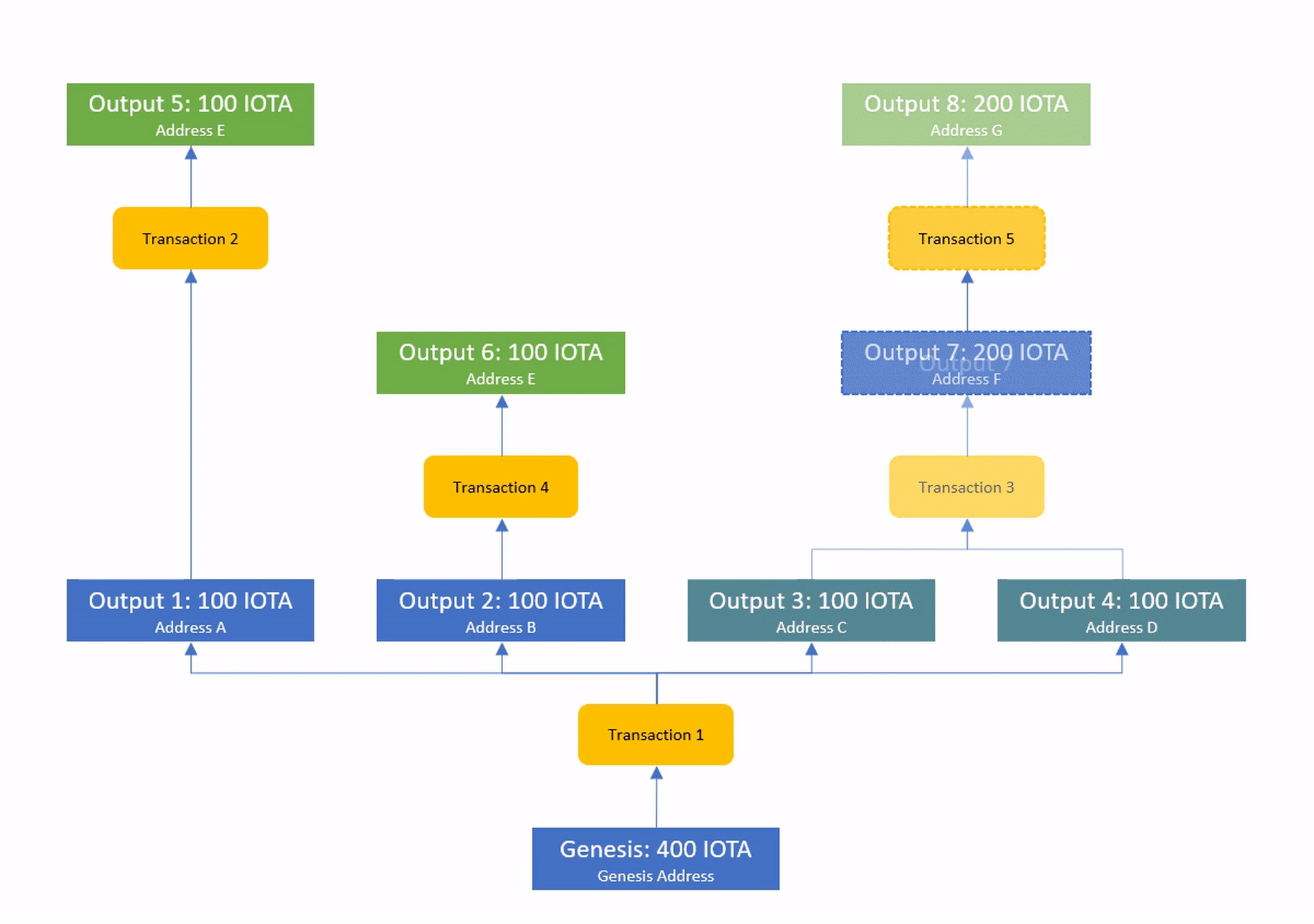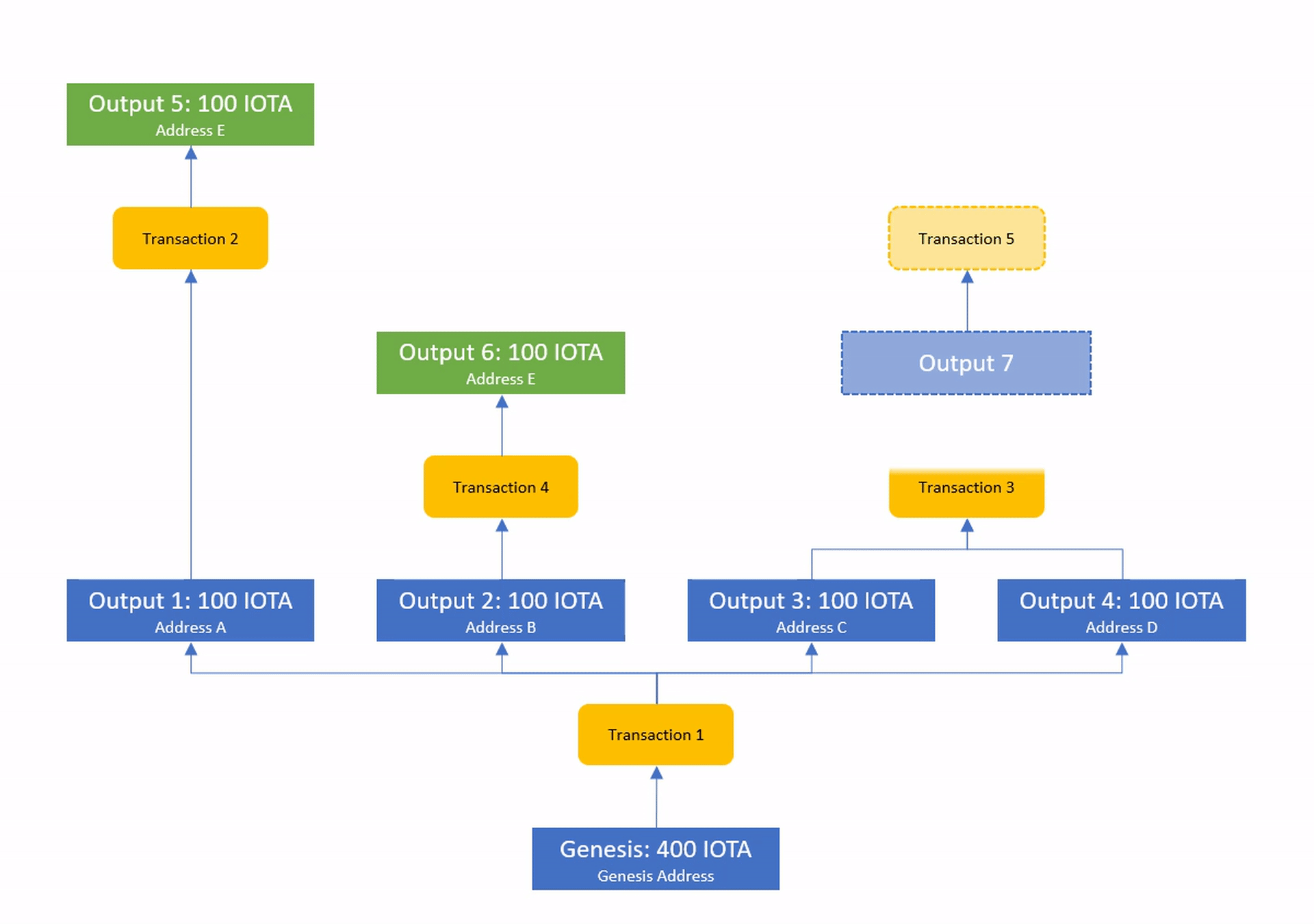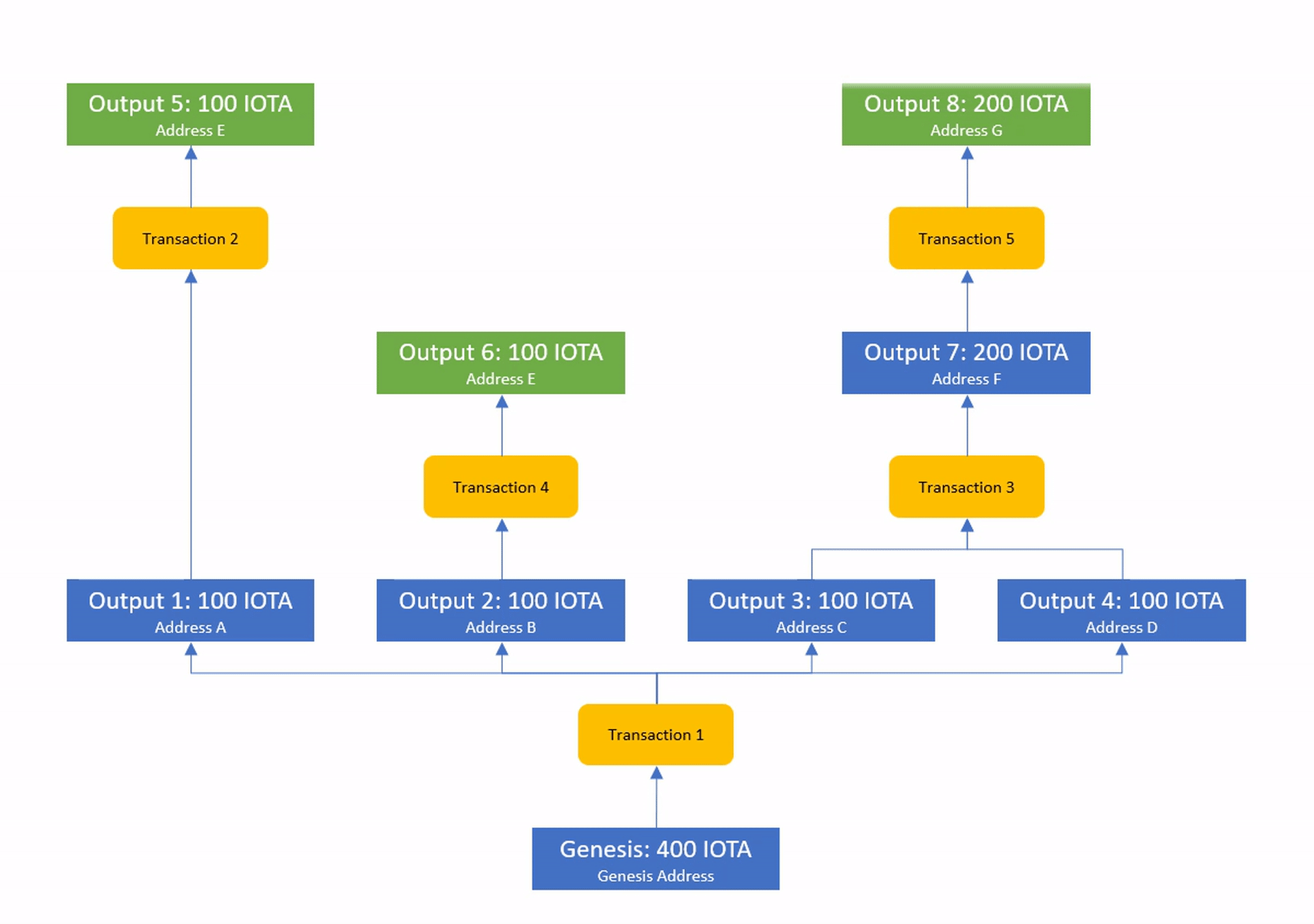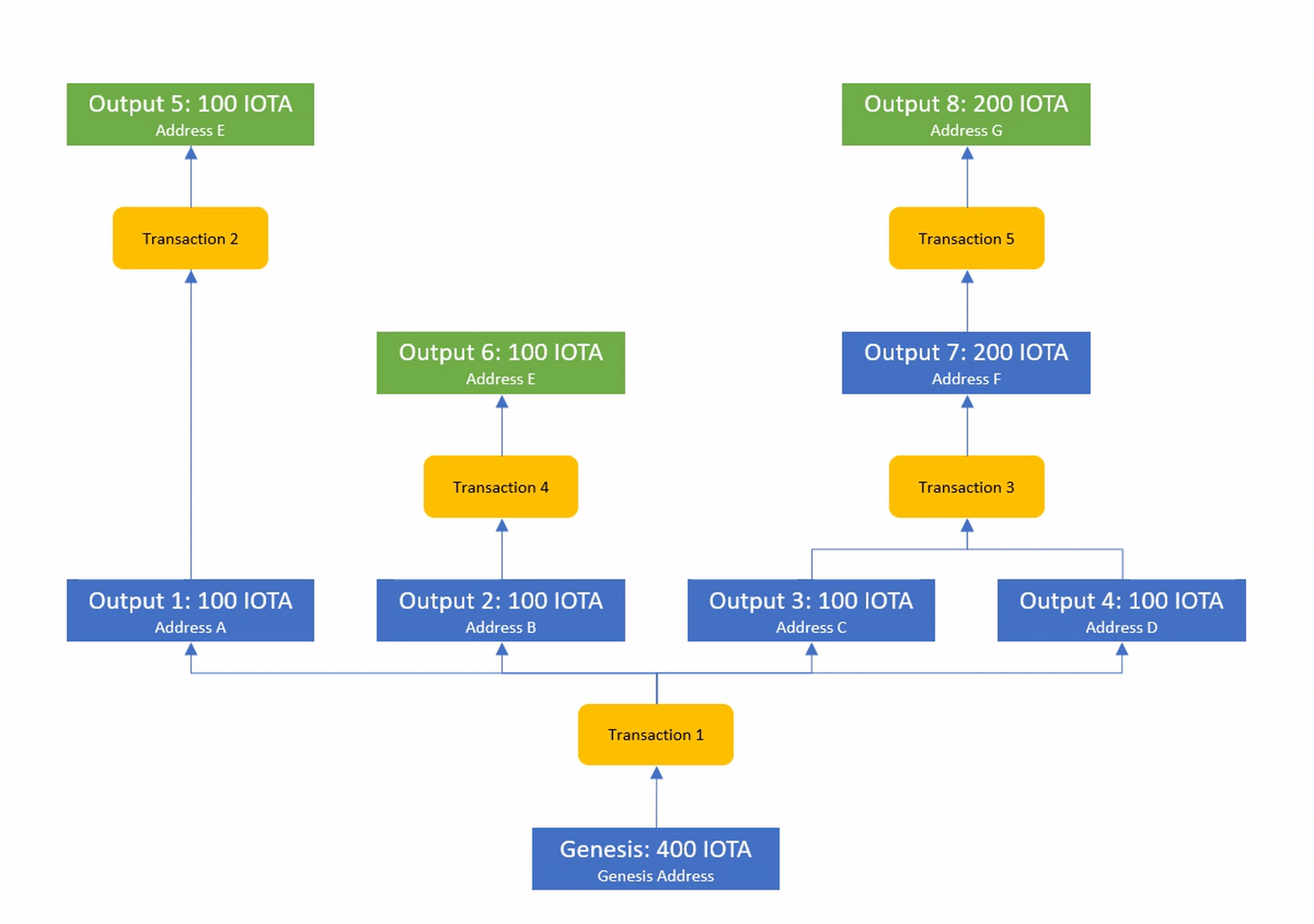
We call transactions whose inputs are known solid and the process of waiting for missing information solidification.
People might ask themselves, why blockchains rely on a total order if their underlying ledger is not dependent on it and the reason is very simple:
The UTXO model has no meaningful way to handle double spends. If a double spend would ever be added to the ledger then the total supply would be increased giving rise to things like unwanted inflation.

The only known way to deal with this problem is to create a shared perception of time which allows the validators to agree, which transactions should be added to the ledger state.
Bitcoins longest chain wins consensus is essentially a voting mechanism on the perception of time — a decentralized clock — which many experts often claim to be the biggest achievement of DLTs.
Quadruple entry accounting
We know from our previous discussions in the 2nd part of this series of blog posts, that the only way to establish a total order is to either make the network synchronous (by artificially slowing it down) or by limiting the amount of validators to a small group.
Considering that virtually all trade-offs in contemporary DLTs boil down to this very fundamental problem, we want to try to approach the double spend problem in a completely different way.
A new form of ledger
Instead of trying to prevent double spends from entering the ledger we want to design a new type of ledger that understands double spends and that is able to track all conflicting ledger state versions at the same time.
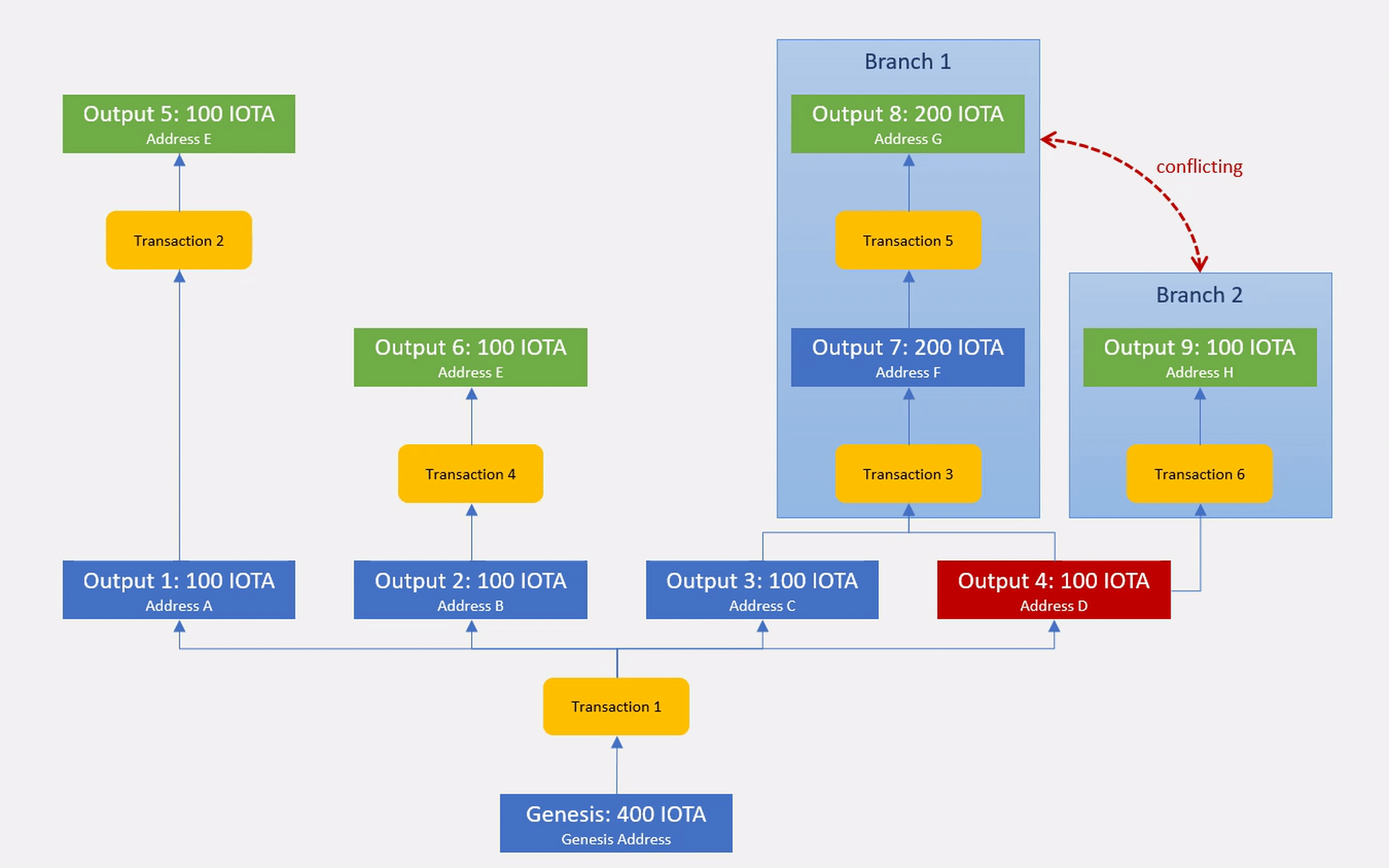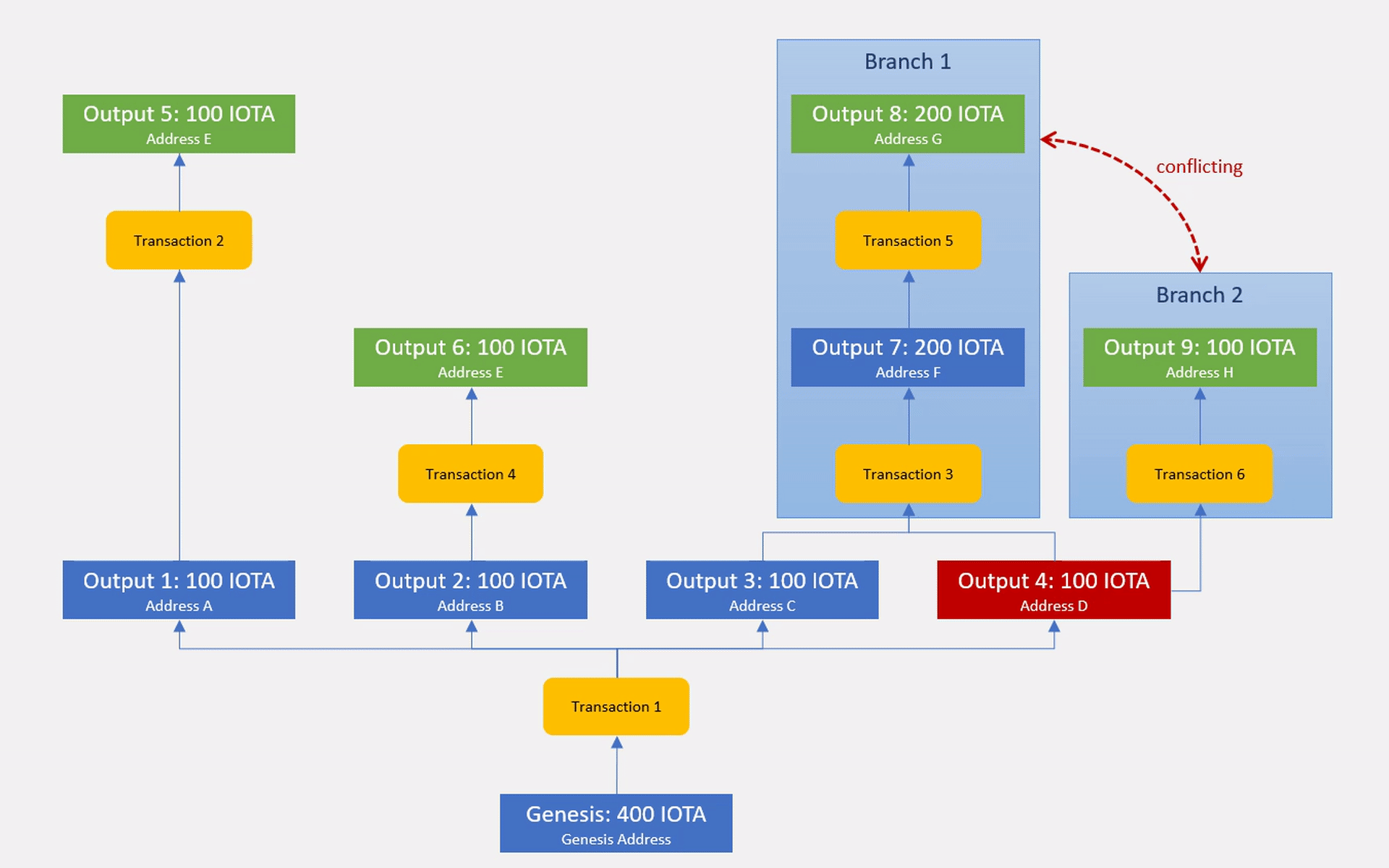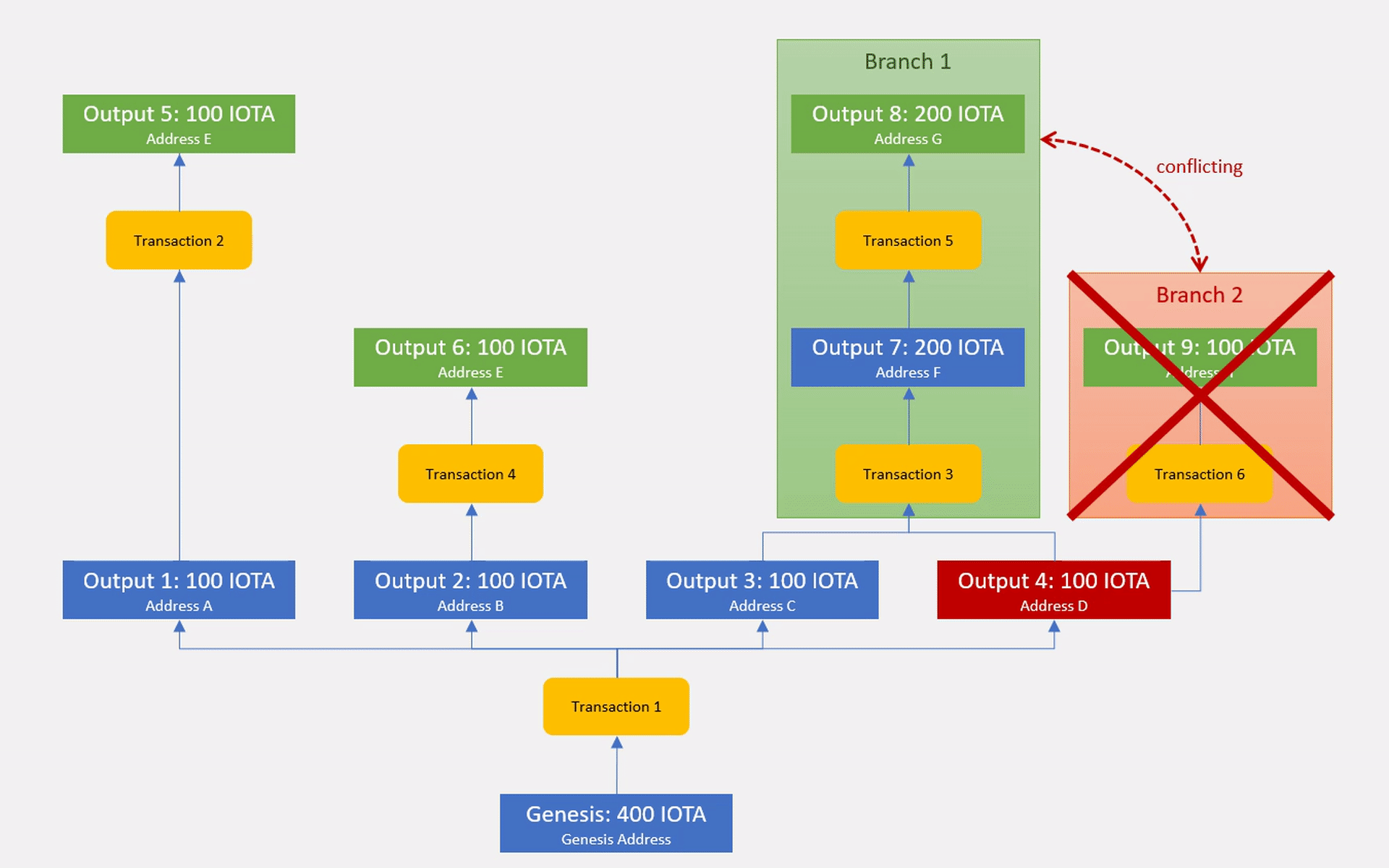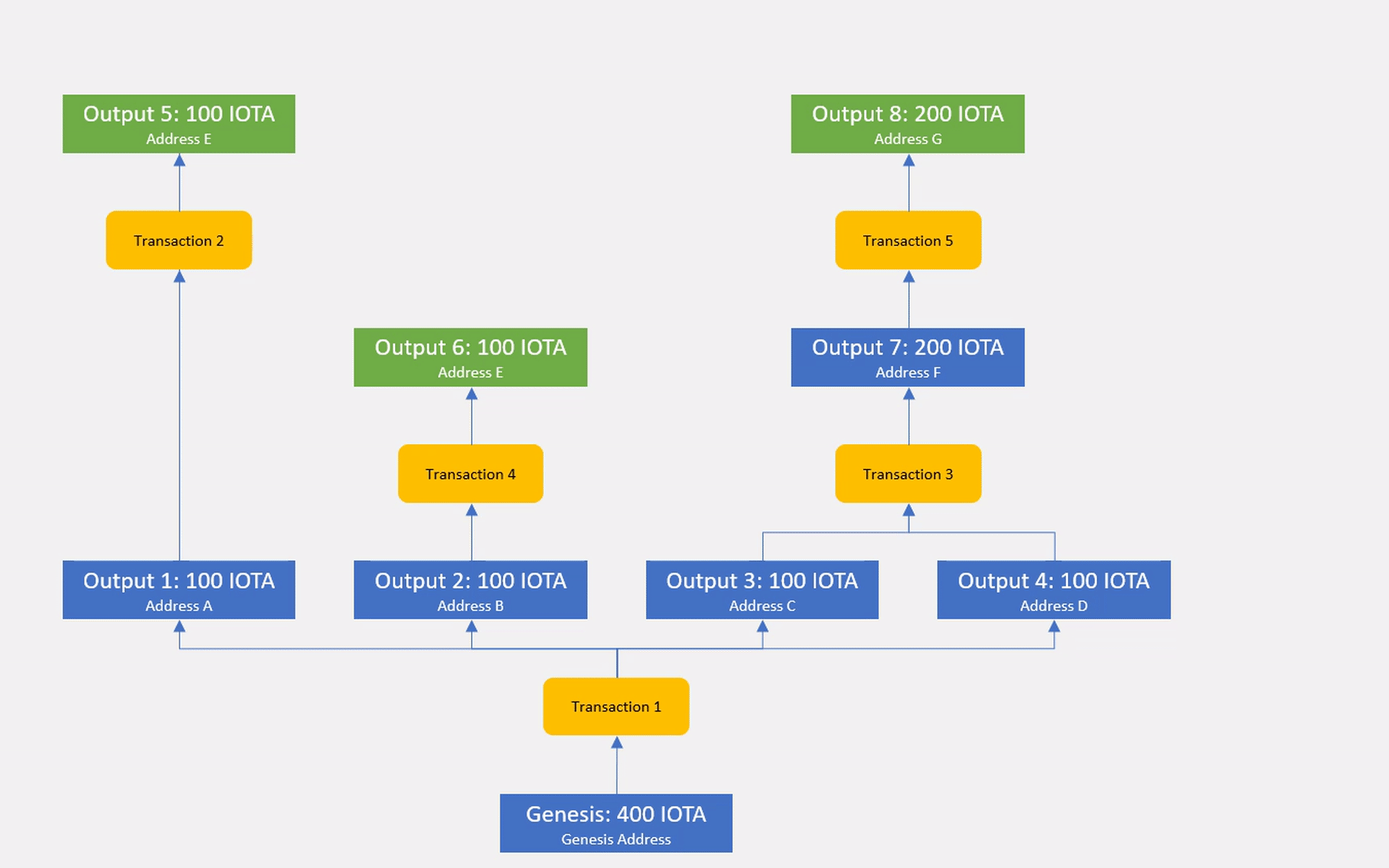
For this, we are going to extend the UTXO model by another dimension (quadrupel entry accounting) where every transaction and every output are associated to a container that represents a specific version of the ledger state. We call this container a branch.

In the absence of conflicts, all transactions and outputs are part of the same ledger state version which we call the master branch. Whenever transactions are found to be conflicting, they spawn a new branch that contains the conflicting transaction itself and all of the outputs that it directly or indirectly creates.

Branches that are formed by transactions spending the same output are part of a conflict set. Since transactions can spend multiple outputs, they can be part of multiple conflict sets.
Outputs inside a branch could be double spent another time, causing branches to recursively form sub-branches. Every branch stores a reference to the parent branch that it split off from, forming the Branch DAG with the master branch at its root. Each branch recursively inherits the ledger state of its ancestors.
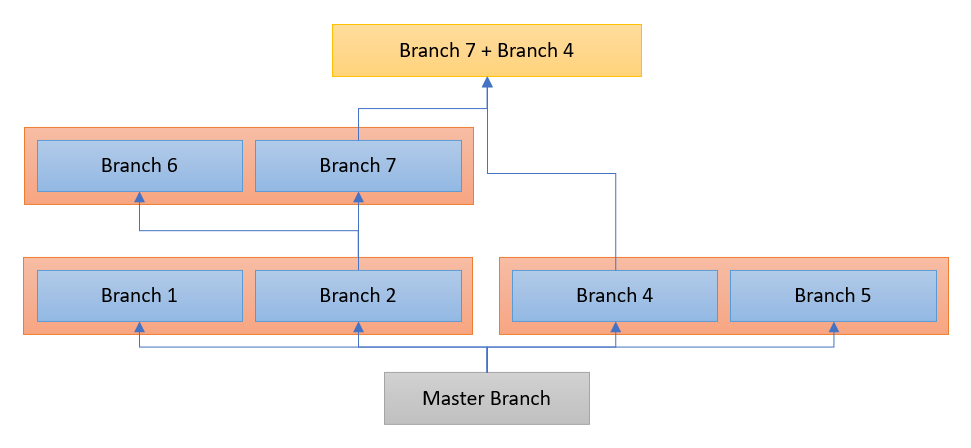
Branches are conflicting if they themselves or any of their ancestors are part of the same conflict set.
When booking non-conflicting transactions, we inherit their associated Branch from the outputs that are being used as inputs. If transactions spend outputs from multiple non-conflicting branches then their outputs are booked into an aggregated branch that acts as a placeholder for the list of underlying conflicts.
On top of this data structure we now define some rules that transactions have to fulfill to be considered valid:
- Transactions need to create exactly the same amount of funds as they consume.
- Transactions may never spend outputs from conflicting branches.
- Transactions may never spend an output that has already been spent by another transaction in their own past (see example).
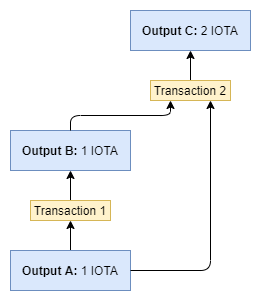
With these 3 rules we can ensure that all ledger state versions will always stay consistent, maintaining a correct total supply.
After having made a decision on a conflict through our higher level consensus mechanism, we can merge the winning branch back into the master branch and prune the conflicting branches that were rejected by the consensus.
This might all sound really complex at first but it is just an efficient way of storing all the different ledger state versions without having to store redundant information. Each output is stored just a single time and storing 1000 conflicting transactions will cost us nearly exactly the same amount of resources as storing 1000 honest transactions (apart from some constant sized overhead for the additional entry in the Branch DAG).
To summarize the new concepts in a few words:
- Branches allow us to tell outputs of different versions of the ledger state apart.
- Conflict sets model the conflict relationships between the branches.
- The Branch DAG allows us to track the causal dependencies between the different branches (to inherit the ledger state and to check for conflicts).
Implications
Instead of having to agree on the fate of each conflict at the time of arrival, we can move the conflict resolution to a higher level, turning the ledger into a data structure that simply tracks all of the state transitions that were proposed by its users (even the conflicting ones).
This allows us to build a DLT where we no longer have to have special entities that protect the ledger against malicious writes (like miners in a blockchain). Anybody can just directly write to the ledger for free just by sharing his transaction with the rest of the network and everybody can update their ledger state completely independent of each other.
All nodes that see the same information are able to construct exactly the same ledger state versions which turns the ledger into a conflict free replicated datatype, that can be updated completely in parallel and without any kind of coordination or artificial slowdowns.
Conclusion
We have designed a new form of ledger that allows us to decouple the processing of transactions and the act of reaching consensus on the existing conflicts.
This results not just in a much more open and democratic ledger design that no longer needs middlemen that protect the act of writing to the ledger but it also removes the need for overly strict coordination between the validating nodes which will later allow us to use Satoshis principles without having to slow down the statements of the validators, causing the act of reaching consensus to become a collaborative process instead of a competitive one.
A large part of the work of the last years went into designing and conceptualizing this form of ledger. The design that now sounds very simple and elegant, was not always that simple as we had no idea how the best design would look like. After a few iterations we are now however confident, that it will not be possible to further simplify these principles any longer.
What this form of ledger proves is that it is not necessary to establish a total order of events to deal with conflicts.
The only reason why contemporary DLTs rely on a total order is because they are using a data structure that doesn’t understand conflicts.
Addendum: Parallels to our physical world
If we look at the behavior of this ledger then we see a lot of similarities to our physical universe and even though it is not directly connected to the topic of DLTs, I think it might be an aspect topic to discuss.
Relativistic Time
Time is a word that we use to describe a perceived series of state changes of a system. The current state is now, the previous state is the past and the upcoming state is the future.
The same definition also applies to how nodes perceive the development of their ledger state in our model and similarly to our universe — nodes have a relativistic perception of time.
Causality
One of the most important concepts in physics is that causality can not be violated, which means that even though time is perceived in a relativistic way, everybody will always perceive the cause before the effect.
This is equivalent to our concept of solidity, where a dependent transaction waits for its inputs to be created before being processed.
Schrödingers Cat
Schrödingers cat is a thought experiment that illustrates a paradox of quantum superposition, where a hypothetical cat in a box may be considered both alive and dead at the same time until a measurement is performed and the box is opened. In that moment the superposition instantaneously collapses to a single specific version.
This is very similar to our model where two conflicting versions can co-exist for some time but the moment we perform a measurement and collect the votes, the two options get instantaneously resolved by merging a single winning version back into the master branch.
Double-slit experiment
Most people are familiar with the double-slit experiment where shining a beam of light through two parallel slits will produce an interference pattern on a screen behind it. This is usually one of the simplest experiments to show that light behaves like a wave and interferes with an obstacle.
If we perform a measurement to determine through which slit each photon goes, we no longer see an interference pattern as the wave function of the photon collapses and it behaves like an ordinary particle. What is really interesting about this experiment is however, that this is even then the case if we perform the measurement after the particle has already passed the slit.
Performing a measurement in the future seems to somehow impact the state of the same particle in the past. There are different interpretations of this observation, but if we assume that the universe tracks it’s state at least similar to the way we track things in our ledger, then this behavior becomes easily explainable.
Performing a measurements and committing to a specific branch of the ledger at some point in the future also means that we are committing to all parents of that branch as each version needs to always stay causally consistent — so, yes deciding on a sub-branch means that we will also make a decision on all of its parents, which indeed influences the past.
Delayed-choice quantum eraser
The delayed-choice quantum eraser experiment is a modification of the previously named experiment that modifies the setup to first measure the photon and then delete the information about the measurement again at a later point in time.
Interestingly, in this case the photons start to behave like a wave again and it somehow restores the previously collapsed wave function back to where it was. It’s not the physical act of measurement that seems to make the difference, but the act of noticing, as physicist Carl von Weizsäcker (who worked closely with quantum pioneer Werner Heisenberg) put it in 1941.
Again our ledger works very similar. If we remove the votes for a specific version and instead cast votes for a different version then the ledger state would perform something we call a reorg and a version that previously looked like it was decided could return back to it’s undecided state.
The act of deleting the information about a performed measurement could be considered to be something like the equivalent of byzantine behavior.
Conclusion
Seeing all these similarities leads me to believe that maybe this way of tracking a ledger is at least similar to the way the universe tracks its state and the first time I publicly stated this was on April 4th 2020 in an interview with a german YouTuber.
Just 10 days later Stephen Wolfram published a new theory of physics that uses exactly these kind of mechanisms to model the physical reality of our universe and I think it is a very interesting fact that two groups of researchers make very similar statements just days apart from each other and most importantly coming from completely different directions.
People interested in Stephens ideas should definitely check out his work!
