

Wrapping my head around Iota & Qubic
Like I did in a previous post, I find the best way to get a better understanding of something is to compare it to something I’m familiar with.
In my case, what I am most familiar with is what I do professionally — building cloud applications on AWS.
How and Why DLTs differ from traditional Cloud
The problem of reaching consensus on the contents of a distributed datastore is nothing new. If you use a cloud datastore like AWS DynamoDB, the chances are that it runs a consensus protocol for nodes to agree on the contents of the datastore.
These nodes are all owned and managed by a single cloud provider, running within the providers data centers. The consensus protocols only need to be effective within this controlled environment.
Distribute Ledger Technologies (DLTs) like Blockchains can’t make these vastly simplifying assumptions. They must assume that nodes running the consensus protocols are distributed around the world, running on highly variant hardware and connected by unreliable networks. They must also assume that some nodes may be malicious, deliberately working against the other nodes.
This is the fundamental reason that DLTs are different to their cloud provider cousins. On top of the usual challenges of consensus they also need to be Byzantine Fault Tolerant (BFT).
Most of the word soup terms you are familiar with like blockchain, DAG, 51% attacks, PoW, PoS etc etc are all related to how the DLTs achieve BFT.
We need to look past these differences to see the similarities.
A DLT is essentially a Key Value Store
Once you strip off how changes are made to a DLT and look at what is stored, then what remains can be viewed logically as a Key Value Store (KVS). In an AWS world an example is DynamoDB.
Wait! WTF happened to the chain of blocks, or the DAG of the tangle?
The structure of DLTs reflect how changes to the ledger are made and agreed upon. I’ll take a closer look at that a little later.
What the keys and values represent varies between DLTs and the usage.
Keys
In Bitcoin the key would be a combination of a transaction hash and the index of an unspent output.
In Iota the keys are known as Addresses and are derived from the private key that owns the address. Ethereum is similar but derived from the public key.
In Iota addresses are 81 chars [A-Z9]. That means 27⁸¹ possible values. So it is an extremely sparsely populated KVS.
Values
In Iota the values are made up of:
- a balance of the iota currency (may be 0)
- some arbitrary data. This could represent a temperature reading from a sensor, an invocation of a qubic (will get that later) or anything you wish.
How ledger changes are made and agreed
So how do we change the values stored against the keys of our DLT KVS?
This is where the fancy structures and algorithms come in.
Nodes don’t so much try to agree on the keys and values of our KVS. What they try to reach consensus on is the entries in a shared ledger.
Entries in the ledger are referred to as transactions and describe changes to values of one or more keys.
Transactions
For example a transaction may contain the following changes:
- subtract 10 iotas from the balance of address abcdabcdabcdabcdabcd…
- add 3 iotas to the balance of address efghefghefghefghefghefgh…
- add 7iotas to the balance of address ijklijklijklijklijklijkl….
Adding transactions to the ledger
Blockchain
In a blockchain users don’t directly add transactions to the ledger. This is done by special nodes called miners.
Users submit transactions to a transaction pool. Miners select some of these to add to a new block. If your transaction is attractive enough (in terms of fees) then the miner may include yours.
In a PoW protocol, the miner now spins some processors trying to guess a hash with a sufficient number of 0’s at the start.
Once they guess the hash, they broadcast this block to other nodes and miners. At this point your transaction is attached to the ledger (as the block it belongs to is attached to a parent block). Note it is not confirmed part of the ledger yet as consensus has not yet been reached.
So transactions are not added continuously, they are added periodically as part of a block. A new block is added to Bitcoin roughly every 10 minutes.
Iota Tangle
In Iota, users attach their transactions to the ledger themselves. They do this whenever they want. This means that transactions are being continuously added to the ledger.
The transactions are attached to the ledger in two places — that is they reference 2 recent existing transactions (called tips).
When the node has attached the transaction, it broadcasts it to all the nodes that it has as neighbours. In turn these neighbours broadcast it to their neighbours and so on till the transaction has propagated throughout the network.
A node’s neighbours are a small subset of all the nodes in existence. Each node typically has a completely different set of neighbours to other nodes and keeps this information to themselves.
By the time your transaction has finished propagating, there is a pretty good chance some nodes have already begun attaching their transactions to yours.
In contrast to the orderly single file process by which transactions are added to a blockchain ledger, the combination of:

- all nodes continuously adding transactions
- the fact that they connect it to two places
- how nodes connect to other nodes (network topology)
- and how transactions propagate
makes Iota a positively chaotic process.
Attacking iota doesn’t simply require enough hash power to produce more transactions than the rest of the network, you also need to get those transactions as quickly as possible to other nodes so they attach their transactions preferentially to yours. This means you need to be very well connected to the other nodes. i.e. you need a lot of neighbours.
At todays scale this is not hard to do, which is why the COO is required. But Iota has grand ambitions. They are not trying to scale to the transaction rate of Visa. Their ambitions are at a scale orders of magnitude greater than that.
Iota wants to be the protocol used by all machines (and fleshy ones like humans) to establish trust in data and to exchange value (in countless micro transactions).
Reaching consensus on the transactions in the ledger
DLTs have different ways to reach consensus and different heuristics to decide when a transaction is considered confirmed.
In Bitcoin, the longest PoW chains wins and transactions are typically considered confirmed when they are 6 blocks deep on the longest chain.
In Iota, transactions are considered confirmed when all the current tips reference it (directly or indirectly). Of course in the chaotic process of adding transactions to the ledger, each node may have a different idea of the set of current tips. Nodes run an algorithm a number of times to give a probabilistic answer.
Event driven processing of changes to Iota ledger
What if we want to trigger some processing when certain addresses change their values in the Iota ledger.
Before we get there lets look at a typical cloud example.
The following diagram shows a simple (admittedly contrived) AWS application. It consists of:
- DynamoDB. The key value store of our application
- Two Lambdas. A Lambda is a function you provide that AWS will invoke when certain triggers occur
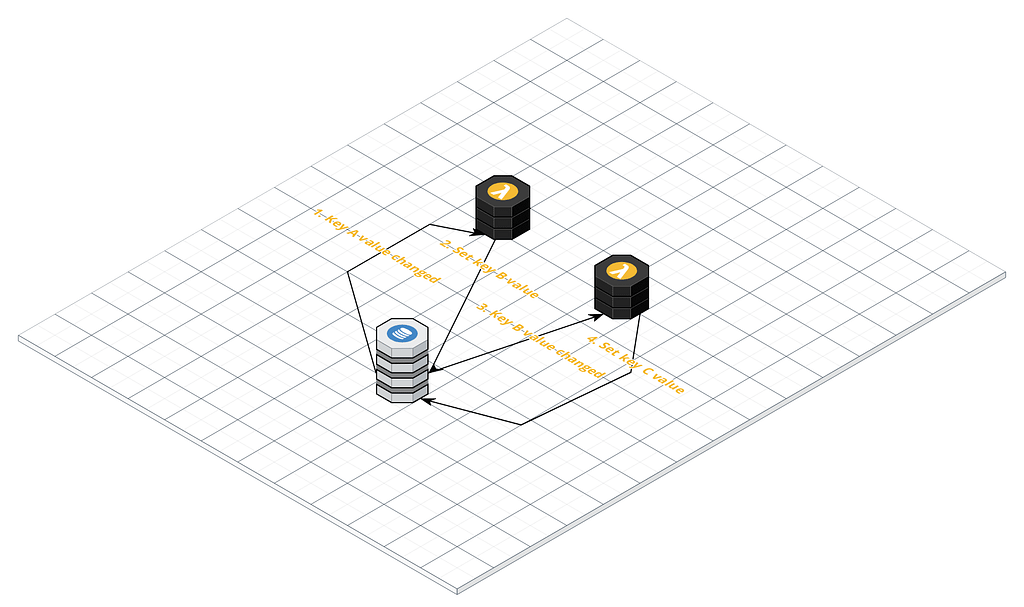
In this example both Lambdas are triggered by changes to our KVS. The flow is as follows:
- The first Lambda triggers when the value associated with key A changes
- It does some processing and sets the value of key B to some value it determined
- The second Lambda triggers when the value associated with key B changes
- It in turn sets the value of key C
This sort of event driven process tends to be rather useful in our cloud world.
If we want to process changes to changes in values at certain Iota addresses, we can modify this architecture as follows:
- Replace the DynamoDB instance by an iota node which we run in an AWS EC2 instance
- react to changes in that data by triggering our Lambdas
Alternatively, if you wanted to customise your Iota node you could in theory use DynamoDB as the KVS for the node. Or you may use it as a way to produce secondary indices that may make certain lookups faster.
There is a whole raft of useful things you could such as processing an Iota payment for some goods.
Note: You can do this today with Iota.
The Iota ledger is a globally distributed shared ledger owned collectively by everyone. The processing however, is entirely private. You own the code for the two Lambdas in the example and you trust AWS to run them for you.
Qubic
What if we want to do some processing that isn’t privately owned and doesn’t require trust in a cloud provider like AWS?
We want the inputs and outputs of the process to be recorded on the Iota ledger.
Unless we have some way to simply determine if the output can only sensibly have been produced by executing our function then we have no way to trust that our code was run correctly and the results recorded faithfully.
We can run it multiple times and then accept one result if a sufficient percentage of results agree.
If we want our function to be able to be run anywhere, not just on AWS Lambda, then we need a way to create functions and the supporting protocols that allow it to be run anywhere.
This is essentially the problem that Qubic is solving. A qubic is essentially a decentralised equivalent of an AWS Lambda.
Part of the Qubic protocol is how you pay / incentivise the nodes (called Oracle Machines) that run your code, just as you pay AWS to do so.
Just as you can do much more in AWS than my contrived example, you can do much more with Qubic too.
Iota is particularly well suited to this sort of cloud like architecture, due to the fact that it supports a continuous stream of transactions, unlike Blockchains that force them into periodic blocks, at the mercy of fees charged.
The values in the Iota KVS change asynchronously and trigger asynchronous processing of functions. Just like typical cloud equivalents.
Conclusion
Comparing Iota + Qubic to a well known cloud alternative such as AWS DynamoDB + Lambda helps to understand how you can make use of them.
- If you have no need to have a shared public datastore or processing then use a cloud provider
- If you need a decentralised datastore but the processing can occur privately then use the Iota ledger together with something like AWS Lambda.
- If you need both the data and processing to be decentralised then use Iota + Qubic.
In the real world, all of these and more will happen.
As always, the more decentralised the more costly and slower it will run.
Just as I don’t need to know too much about the nuts and bolts of how the AWS components like DynamoDB and Lambda are implemented, in time we will stop caring too much about the nuts and bolts of how DLTs achieve their decentralisation. It will move into the background and we will be more concerned with the properties they provide (scalability, security, performance, tooling, developer experience, cost etc).
I expect that, over the coming years, as Qubic is built out and Iota matures and scales, building applications on it will feel increasingly similar to building cloud applications. That is a good thing.
