

The Trust Machine — Part2: A model of the entire DLT space
Designing humanities trust layer for the digital world
In the last part of this series of blog posts, we discussed how scarce resource based sybil protection mechanisms are responsible for the scalibility trilemma and how a different form of sybil protection that uses real world trust promises to overcome these and other limitations.
Before continuing to introduce the missing parts of the specification, I want to take a short detour and develop a model that allows us to classify not only all existing but also potentially undiscovered consensus mechanisms.
This model will not only guide our design decisions along the way but it will also make it easier to understand why I consider the proposed consensus mechanism to be superior to existing solutions.
The Fundamentals
To be able to develop such a model, we first need to understand some fundamental facts about distributed ledgers.
1. Two forms of communication
All existing DLTs use two forms of communication that have different properties.
1.1 Point-to-point communication
The point-to-point communication is based on directly contacting a peer using a dedicated connection. It can be compared to dialing the number of your grandma and then talking to her on the phone.
The benefits of this form of communication are that it is very fast and it is possible to exchange personal information.
The downsides of this form of communication is that it doesn’t scale very well with large networks (imagine having thousands of phone calls at the same time) and that it is necessary to publish ones phone number (IP Address + Port) which opens up attack vectors like DDOS attacks where attackers are constantly calling our number to prevent honest connections from being established.
1.2 Gossip protocol
The gossip protocol is based on the point-to-point communication but instead of contacting each network participant individually, nodes have a limited amount of neighbors that they exchange messages with.
Any received message is forwarded to the neighbors. If the amount of neighbors is larger than 1, then the messages spread exponentially fast to all of the network participants.
The benefits of this approach are that it is reasonably fast, that it is not necessary to reveal ones address to all network participants and that it scales to an arbitrary large network.
The downside of this approach is that it is not possible to exchange personal information — all nodes will see exactly the same messages.
2. Nodes in a DLT have a relativistic perception of time
Nodes in a decentralized network are by definition spatially separated (distributed). Since information can only travel at a maximum speed, they will naturally see messages in a different order.
The reason is pretty obvious: Since nodes are computers that exist in our universe, they inherit the same physical limitations that exist in our universe and they therefore also inherit an equivalent of the relativity of simultaneity where different coordinates in the network (nodes) have a different perception of time.
Trying to build a consensus mechanism that anyway tries to establish a total order of events (like blockchain) is possible but somewhat against the nature of how the nodes perceive their universe.
In fact, the only way to establish a total order is by either limiting the size of the universe (number of validators) or by artificially slowing down the messages which makes the network become synchronous.
3. Consensus means voting
A direct consequence of nodes seeing messages in a different order is that to reach consensus in the presence of conflicts, we need to vote which of the conflicting messages is supposed to win.
This means that every existing consensus mechanism is ultimately a voting mechanism and the quest for the best DLT is accordingly the quest for the most efficient and flexible voting mechanism.
Now that we have established these basic facts, we can continue to develop our model by comparing two of the major consensus mechanism.
Classical consensus
Against popular belief, consensus research did not start with Satoshi in 2008 but decades earlier in the 1980s with the work on the algorithms of the Paxos family and its successors. Early on, these algorithms provided only fault tolerance (resilience against crashed or non-responsive validators) but were later extended to be secure against arbitrary byzantine faults (validators that are lying or actively trying to break the system).
These algorithms do not just provide very fast finality times (with deterministic finality) but they are also very well researched and provably secure against 1/3rd of bad actors.
Compared to Nakamoto blockchain, they do however have some drawbacks, which is most probably the reason why we haven’t seen the DLT revolution much earlier:
1. They only work with a few dozen validators
The algorithms are based on knowing the opinions of all other validators which requires nodes to regularly query each other using a point-to-point communication.
This has exponential messaging complexity which means that the throughput required to maintain consensus gets too large in larger networks.
2. They only work in a fixed committee setting
All network participants need to agree upfront on the identities of all validators which prevents a naive deployment in an open and permissionless setting.
3. They are vulnerable to DDOS attacks
The protocols are based on directly querying each other using the point-to-point communication protocol which makes them susceptible to DDOS attacks.
This in combination with the fact that the amount of validators has to be small makes it relatively easy to take down the whole network by just attacking a few validators (1/3rd which can be expected to be somewhere around 7–11 nodes).
Nakamoto consensus
For a long time it seemed like we knew everything about consensus and its limitations until something unexpected happened.
In 2008 Satoshi Nakamoto published his bitcoin whitepaper which elegantly solved nearly all of the named problems.
The biggest breakthrough of Bitcoin was the introduction of a voting scheme on top of a blockchain (a data structure invented by Stuart Haber and W. Scott Stornetta in 1991) that could efficiently be replicated between nodes using the gossip protocol.
Blocks that are issued by block producers in regular intervals, contain the state changes that are added to the ledger and a reference to the block of the previous block producer. Through this reference, the blocks form a chain where every block implicitly approves all of the previous blocks which represents a vote by the issuer on what he perceives to be the correct chain. The chain that received the most votes (longest chain) wins.
Instead of all nodes regularly contacting all of the validators, it relies on periodically considering the opinion of just a single randomly chosen validator whose statement is added to the blockchain and replicated to all other network participants.
Benefits
These two small changes (considering only a single opinion and using the gossip protocol to distribute it) had a huge impact on the properties of the consensus algorithm:
1. Unlimited network size
Due to the ability to use the gossip protocol, Nakamoto consensus scales to an unlimited amount of nodes.
2. Trust-less verification
Since the blockchain is replicated to all network participants (even to the ones that are not actively taking part in creating blocks), they have access to the same information and can apply the same state changes. Furthermore it is possible for nodes that were offline or that are joining the network later to download all of the previous blocks and arrive at the same conclusion without having to trust a 3rd party.
3. Immutability
Since blocks are linked together via hashes, the content of the blocks becomes immutable. Changing even a single bit will cause the containing block to change its hash and break the chain.
4. The byzantine threshold is higher than in classical consensus
Instead of being able to tolerate only 33% of malicious actors, Nakamoto consensus is able to tolerate 50% of bad actors.
5. Robustness + dynamic availability
Since nodes communicate using the gossip protocol, the IP addresses of the validators do not have to be publicly exposed to everybody. This makes it very hard to take down individual actors or harm the network by performing things like DDOS attacks.
Furthermore, the network will continue to function even if a significant amount of block producers are leaving the network.
6. The network can be open and permissionless
Instead of having to agree on the identities of all validators, the network participants only need to agree if the blocks they are seeing are legitimate. In combination with Proof of Work, this enables the network to become open and permissionless without having to establish a shared perception of identities.
7. Flexibility + level of freedom
The real beauty of this voting scheme is however its flexibility. Instead of being limited to just Proof of Work, it gives you complete freedom over the way how the block producers are chosen.
This kicked off a whole field of research trying to choose block producers more efficiently. Today we have PoW chains (Bitcoin), PoS chains (Cardano), VDF chains (Solana), permissioned chains (Hyperbole), semi-permissioned chains (EOS) and all kinds of other variants.
This level of freedom and flexibility is the reason why 99% of all DLTs use a blockchain.
Trade offs
Even though, Nakamoto consensus has a lot of really compelling features and is the first approach that enables robust distributed consensus in large scale networks, it also has it’s trade offs:
- Probabilistic Finality
The first trade off that Nakamoto consensus makes compared to Classical consensus is that it uses a probabilistic finality. This means, that things in Nakamoto consensus never get really final (just harder and harder to revert). In Bitcoin, things are usually considered to be final once they are approved by 6 blocks. - Slow confirmations
Since things have to be confirmed by a certain amount of blocks before they can be considered to be “irreversible” and since blocks have to be issued with a relatively large delay, it takes a really long time until things can be considered to be confirmed.
Defining the model
The two named consensus mechanism are so different in their properties that they are very likely at opposite ends of the DLT spectrum.
Following this assumption, we choose the two most striking differences —the form of communication used for the voting and the amount of considered validators — as the cornerstones for our model.
The result is a 2-dimensional space with 6 quadrants where only 5 out of 6 represent viable options for DLTs and one is the classical centralized client / server architecture that we know from services like PayPal or Visa:
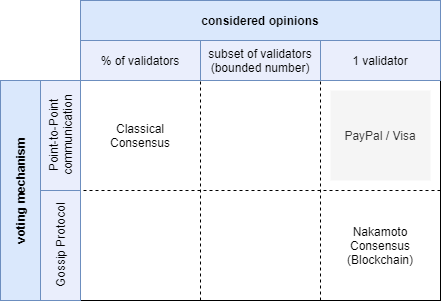
I claim, that just by looking at these two aspects of a protocol, we can derive nearly all of its features and trade-offs. Furthermore I claim that depending on which space a project occupies in this model, it can only get worse but never better than what its quadrant imposes regarding the drawbacks and limitations.
It is possible to combine approaches of different quadrants to get the best of multiple worlds but this will also lead to the inheritance of the corresponding drawbacks and trade-offs.
Let’s have a look at some of the most important metrics for DLTs!
Probabilistic vs deterministic finality
One of the simplest and most obvious classifications is the separation between protocols that have a:
- deterministic finality, which means that things are truly final and there is no chance for rollbacks in the system.
- probabilistic finality, which means that things get harder and harder to revert but they will never get truly final.

If every node in the network knows the exact opinion of each validator then there is no way for any of them to ever come in and pretend that he actually meant something else.
If we do however only consider the opinions of a subset of all validators, then there might be a small but non-zero chance that we initially heard a minority opinion. Rollbacks are therefore possible but become less and less likely.
While probabilistic finality sounds inferior at first, it is usually considered to be equally secure because it allows for a higher amount of malicious nodes (50% instead of 33%) and a larger network (more on that later).
Time to finality
Another important metric is the time that it takes for transactions to be finalized.
The more opinions that can be gathered in a given time frame, the faster it is possible to reach a point where all nodes in the network have a similar perception of the majority opinion.


Accordingly, all consensus mechanisms that do not limit the amount of gathered opinions to just a single one, should have reasonably fast confirmation times.
Scalability (supported network size)
Every DLT is based on a peer-to-peer network of distributed nodes where at least some of these nodes act as validators (or consensus producers).
To analyze the scalability of the network in regards to the supported amount of validators and nodes, we will look at each quadrant individually.

Point-to-Point communication / all validators:
This quadrant represents the most well researched class of consensus algorithms — the classical consensus algorithms.
We know from our earlier discussion, that they only support very small network sizes of a few dozen nodes (due to an exponential messaging complexity).
Gossip protocol / all validators:
Since this type of DLT still considers the opinions of all validators, it inherits similar limitations as the previous category. The use of the gossip protocol can however be considered to be potentially more efficient which should increase the scalability of the previous category by around 1 order of magnitude which means that such a DLT should be able to handle up to around 1000 validators (with a potentially unlimited amount of consensus consuming nodes).
Point-to-point communication / subset of validators:
Since the amount of gathered opinions is bounded, we expect the messaging complexity to be bounded as well.
This means that the supported network size is theoretically unbounded. This is however only true if the load of querying each other for opinions can be equally distributed between all nodes. If there would for example be a validator that has more influence than others, then this node would be queried more often.
There is not a single sybil protection that produces a perfectly equal distribution of weight. This means that the network size can be larger than the previous two categories but it is still bounded for all practical purposes.
Gossip Protocol / subset of validators (including a single one):
This class of consensus mechanisms distributes the opinions via gossip which means that all nodes will eventually see the same messages. The result is that even validators that have a lot of influence in the consensus will only have to send their opinion a single time without having to be queried by every node.
The result is a network that scales to an unlimited amount of nodes and validators.
Security & Robustness
Another very important metric is the security and robustness of the protocol and following the last example, we are going to discuss every quadrant individually.
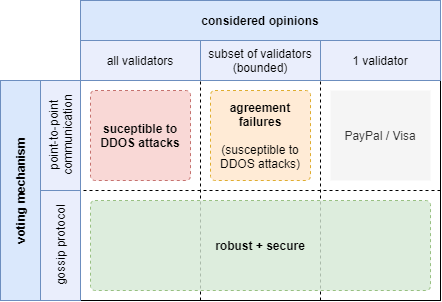
Point-to-Point communication / all validators:
The biggest problem of this quadrant is the very small amount of validators that have to expose themselves by publishing their IP address. Accordingly it becomes very easy to attack the network with things like DDOS attacks.
Gossip protocol / all validators:
The relatively large amount of supported validators in combination with the fact that nodes can mask their IP address through the use of the gossip protocol allows this family of consensus mechanism to be robust against external attacks.
The fact, that the opinions are replicated via gossip will additionally ensure that all nodes see the same messages and come to the same conclusion which should rule out things like agreement failures.
Point-to-point communication / subset of validators:
Nodes are exposing their IP address as part of the protocol which makes them susceptible to DDOS attacks. This does however only pose a threat to the nodes themselves rather than the network as a whole since the amount of supported validators is potentially large.
The fact that nodes form their opinion based on a subjective perception of the world does however allow things like agreement failures to happen. It is possible to make the chance relatively low but it is impossible to rule them out completely.
Gossip Protocol / subset of validators (including a single one):
This category can be considered to be home to the most secure and robust consensus mechanisms that we know.
The use of the gossip protocol does not just rule out agreement failures but it also allows nodes to hide their IP address as part of the gossip protocol which makes it hard to attack individual nodes and therefore the network as a whole.
Level of freedom (sybil protection)
The DLT revolution was started by lowering the requirement for an absolute consensus on the identities of the validators to an absolute consensus on the weight of the gossiped messages.
It sounds like a small change but it enabled the integration of an external sybil protection like Proof of Work. Since we want to build a DLT that directly uses trust, this is one of the most important metrics and we are again going to discuss the quadrants individually.

All validators:
The consensus mechanisms that are based on gathering the opinions of all validators obviously need an absolute consensus on the identities of these validators.
Point-to-point communication / subset of validators:
The idea of gathering the opinions of a subset of validators aims at getting an estimate of the opinions of all validators. This estimate will obviously not be 100% accurate which means that the consensus mechanisms needs to have a way to account for this kind of imprecision.
If they allow for an imprecision in gathering the opinions, then they are potentially also able to deal with an approximate consensus on the weight of the validators.
Gossip Protocol / subset of validators:
Similar to the previous category, we expect these consensus mechanisms to potentially be able to deal with a certain imprecision in the gathered opinions.
The use of the gossip protocol does however increase the level of freedom slightly by only requiring an approximate consensus on the weight of the circulated messages.
Since all nodes will eventually see the same messages, we can allow for some additional imprecision in the perceived weight of the validators.
Gossip Protocol / 1 validator:
If nodes are only meant to consider the opinion of a single validator, then we need to have a way to deal with conflicting statements of different validators.
The only way do decide between these kind of forks is by having an absolute consensus on the weight of each statement.
Summary
We have introduced a model that allows us to classify DLTs into 5 different categories. These categories dictate most of their fundamental properties (independently of the remaining design decisions).
The following graphic shows an overview of the examined properties — with a color coding that goes from green (good) to red (bad):

The amount of consensus mechanisms that are not a combination of multiple different approaches is relatively limited. The following graphic shows some of the most important ones:

Implications
Nakamoto consensus is the most robust, most secure and most scalable consensus mechanism that we know and the probabilistic finality through a replicated data structure like the blockchain has not only provided us with a tool that completely eliminates agreement failures but it has also proven itself to be secure as long as more than 50% of the validators are honest.
But while this seems to be very beneficial for an unsharded system, it becomes a huge blocker for sharding.
Since a blockchain by definition tracks a single longest chain, the only way to shard such a system is to run multiple instances of them in parallel. The consequence is that there needs to exist some form of communication protocol between the shards. Otherwise it would be impossible to move funds between shards and they would be completely isolated.
To enable the transfer of funds between shards we however either need a precise perception of finality (which is by design missing in Nakamoto consensus) or the ability to perform cross-chain rollbacks, which is considered to be hard to implement in a reasonable way.
The only way to reliably shard such a system would be to have really pessimistic assumptions about the length of possible rollbacks. This is the reason why drivechains (one of the scaling proposals for Bitcoin) require multiple months to transfer funds between two shards.
But it is not just the shardability, that poses a problem. The slow confirmation times prevent a lot of use cases related to crypto being used as a form of digital cash. It is completely infeasible to wait multiple minutes or even hours to have a transaction confirmed. The famous “buying a coffee with Bitcoin” example shows that for a lot of real world use cases we need faster confirmations.
The emergence of Bitcoin maximalism
The realization, that a new technology can only be successful if it is better than existing solutions, in combination with the previous observation, led to a huge rift in the crypto community.
On one side there are the crypto enthusiasts that envision DLTs to play a major role in humanities future and that want to make this technology become a success at any cost, and on the other side there are the bitcoin maximalists that are not willing to make any trade-offs when it comes to the security or robustness of the system.
They argue that we already have a working fiat system for day to day payments and the only thing that is really missing is a secure store of value. They don’t see Bitcoin as a medium of exchange, but as a way to transport value over time.
These arguments do make sense but only if we assume that there is no other solution to the named problems that we simply haven’t found, yet.
Hybrid solutions
To overcome these limitations, most contemporary DLTs try to combine different solutions to get the best of multiple worlds.
The most popular approach is currently, to randomly select a small subset of all validators to be the consensus producers for some time (an epoch) and let them run a classical consensus algorithm. They propagate their decisions as part of blocks in a blockchain which enables these projects to combine the fast and deterministic finality required for sharding with the scalability of traditional blockchains.
By using a classical consensus algorithm on top of a blockchain, they do however not only become much more complex but they also trade parts of what made Nakamoto consensus robust for faster confirmations. This is one of the reason why Bitcoin maximalists are not very fond of a lot of the existing next-gen projects.
And in fact, a lot of these newer blockchain projects would face massive problems if there would ever be a point where 1/3rd of the randomly chosen validators (around 7–11 nodes) would fail to produce consensus statements in time.
Some of them would simply stop to confirm transactions (i.e. ETH 2.0) while others would halt completely and would have to be restarted with a hard fork (i.e. Cosmos).
Considering that the goal of DLT is to create a technological foundation for the monetary future of humanity, these trade-offs seem to be very problematic.
As long as DLTs are mainly used for investment purposes it might not be that critical to accept these trade-offs but as soon as we are talking about integrating them into our economy by using them as a medium of exchange, this fragility poses a huge threat to the whole society.
Imagine a foreign actor being able to cripple the economy of a whole country by DDOSing a hand full of nodes before a war. The fact that these nodes are envisioned to be run by average people who are not necessarily experts in protecting their infrastructure against sophisticated attacks, makes this problem even worse.
The unexplored quadrant
If we look at our model, we realize that there is a single quadrant (subset of validators / gossip protocol), that is currently not covered by any consensus mechanism.
This quadrant does not just solve the drawbacks of Nakamoto consensus without any additional trade-offs but it also offers the largest flexibility when it comes to the used sybil protection mechanism.
The statement that there is no existing consensus mechanism that is operating in this quadrant is actually not correct because there are currently two projects that are working on such a consensus mechanism.
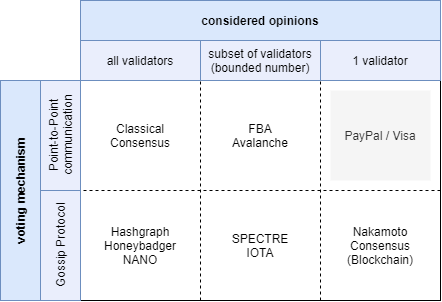
One of them is the SPECTRE protocol which uses a BlockDAG to allow validators to issue confirmations in parallel and the other one is IOTA that is completely block less.
While SPECTRE definitely increases the scalability of the original Nakamoto consensus, it still requires an absolute consensus on the weight of the messages to decide between confliting statements. This enforces the use of a scarce resource based sybil protection like Proof of Work with all of its drawbacks
Only a block-less protocol like IOTA that is able to vote on the fate of every single transaction individually is able to completely leverage all of the benefits of the given quadrant and is therefore potentially able to directly integrate trust into the DLT.
By using Cardanos EUTXO model, this block-less architecture is even able to directly model smart contracts (without a perception of total order). The state can can be placed out in the open in the form of an output without relying on an instance that establishes a total order of all requests. If two entities want to consume the same state at the same time, then the consensus mechanism will ensure that only one of them is successful.
Conclusion
We have developed a model that allows us to judge the potential benefits and drawbacks of different consensus mechanisms independent of their specific design decisions.
By comparing the potential benefits and drawbacks with the actual benefits and drawbacks, we can identify inefficiencies in the design of the corresponding DLT.
This will help us to judge the design decisions of the following blog posts and allow us to get an understanding of how close IOTA is to the actual optimum that you could ever achieve.
