

The Trust Machine — Part4: The Tangle — a generalized voting protocol
Designing humanities trust layer for the digital world
In the last part of our series of blog posts we introduced a new ledger model that allows nodes to understand the causal relations between conflicts.
In this part we are going to extend the theoretical models used to describe distributed systems with a new primitive — the generalized voting protocol — and then provide the specification for an instance of this primitive, that uses the newly gained freedom to achieve the optimal protocol performance.
Theoretical Model
In an attempt to develop a theoretical model of the components used in distributed systems, the field of distributed computing research has identified a collection of fundamental building blocks.
These distributed computing primitives are generalized, high level abstractions of protocols that are completely agnostic to their actual design and implementation.
This abstraction does not just allow researchers to compare and study the performance of different solutions solving a similar problem but it also allows to create modular software, where individual elements of the system can be exchanged when new and better solutions become available.
Atomic broadcast
One of the most prominent distributed computing primitives, related to the field of consensus, is the atomic broadcast.
It describes a protocol that ensures that all nodes in a distributed network receive the same set of messages — hence broadcast — in exactly the same order. It is called atomic because the protocol can either succeed at all participants, or halt for all participants.
Note: There are several different protocols that implement this primitive but the most prominent ones are most probably Hashgraph and HoneyBadger.
Generalized voting
We have already discussed how establishing a total order is directly responsible for the limitations of contemporary DLTs and we accordingly want to propose a different, more generalized primitive that does not depend on a total order.
We call this primitive generalized voting and it describes a protocol that ensures that all participants in a distributed network eventually receive the same set of messages and in the presence of conflicts in these messages, eventually decide for a single version of truth.
This primitive is generic enough to cover all forms of consensus (including Satoshis original blockchain design) which is a good indicator for it being a true primitive.
Note: The atomic broadcast protocol turns out to be a specialized version of the generalized voting protocol and therefore “not really” a true primitive as it makes assumptions about the underlying design (namely to resolve conflicts by establishing a total order).
After having introduced the theoretical foundation for our new voting protocol, we will now continue with providing the missing parts of the specification.
We will introduce the concepts step-by-step in a bottom-up fashion starting with the networking layer and then extending the concepts to also cover consensus.
Networking Layer
Similarly to other DLTs, we use a peer-to-peer network where nodes communicate with a fixed amount of neighbors.

The neighbor selection can happen through manual mutual peering, by using an automatic peer discovery or a combination of the two.
Note: IOTA provides a default peering strategy that allows nodes to find neighbors automatically and without user intervention.
Gossip Protocol
Since our protocol is based on the principles of the quadruple entry accounting, writing to the ledger is as easy as broadcasting a transaction to the network.
Accordingly, a node that wants to issue a transaction, sends a message with the transaction to all of its neighbors, who will update their ledger and pass on the message recursively.
This form of communication is called gossip protocol and since it is based on exchanging information with only a fixed amount of neighbors, it scales to an unlimited amount of participants.
Crash Fault Tolerance
So far our protocol is scalable, but it is not yet reliable as there are several situations that could prevent a node from receiving all messages (e.g. being offline or malfunctioning).
To solve this problem, we are going to use Satoshi Nakamotos idea to make the messages form a DAG (directed acyclic graph), where later messages reference earlier ones. In contrast to a blockchain where each block references only a single other block, a message in IOTA references two parents which allows us to get rid of the need for establishing a total order.

A node that receives a message that references an unknown parent can request the missing message from its neighbors. This simple mechanism ensures, that even nodes that have been offline for some time will be able to recursively request the messages they missed out on, as soon as they come back online and receive recent messages.
The act of recursively requesting missing messages is called solidification and a message that has no gaps in its direct or indirect ancestors is called solid.
The ability of a distributed system to deal with unreliable participants communicating over an unreliable medium is called crash fault tolerance.
The Tangle
Since the resulting DAG looks a little bit different than a blockchain, we want to take some time and introduce some additional terminology.
The first message that bootstraps the network is called the genesis message and nodes reference it when there are no other messages to reference. It is marked as solid by default.
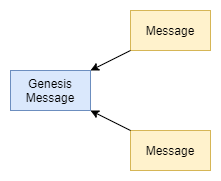
Messages that have not been referenced by other messages yet, are called tips and the process of settings these references while issuing a message is called tip selection.
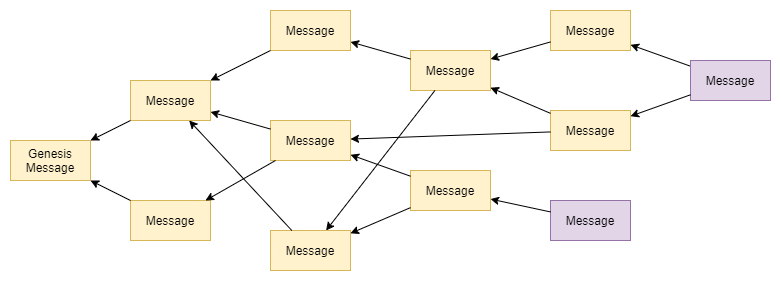
All messages that are directly or indirectly referenced by a message are called its past cone.
Accordingly, all messages that directly or indirectly reference a message are called its future cone.
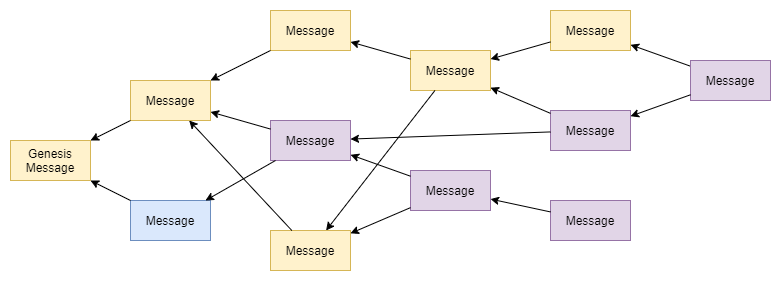
Messages that only get seen by a very small amount of nodes have a lower chance to be referenced by later messages and in rare edge cases, it can happen that the message will not be referenced at all.
We call these messages orphaned and they are cleaned up once it becomes clear nobody is going to reference them anymore.

Conclusion
We have specified a very simple broadcast protocol that ensures that each node is eventually going to have a similar perception of the messages that have been processed by the network (orphans are ignored).
Instead of constantly monitoring each participant and halting the network if too many nodes have problems— like in an atomic broadcast protocol — we give nodes the ability to catch up.
Note: This very simple idea of giving nodes the ability to catch up was one of Satoshi Nakamotos biggest breakthroughs.
It doesn’t just allow nodes to reliably bridge times of suboptimal network conditions but it also allows anybody to leave or join the network whenever they want — it is truly open and permissionless.
Consensus Layer
So far, our protocol is extremely simple and only requires to send two additional hashes with each transaction but we have also not really addressed the hard problem of consensus, yet.
While reaching consensus is usually considered to be a really complex topic, we will see that our protocol is actually done already and just needs some minor adjustments to also provide consensus.
Understanding Satoshi
To understand the following sections, we first need to change the way we look at blockchains.
Instead of seeing them as a single longest chain, they can be seen as a tree where all the abandoned forks are still visible and where the outcome of the voting about which fork should prevail is counted in the length of the competing chains.
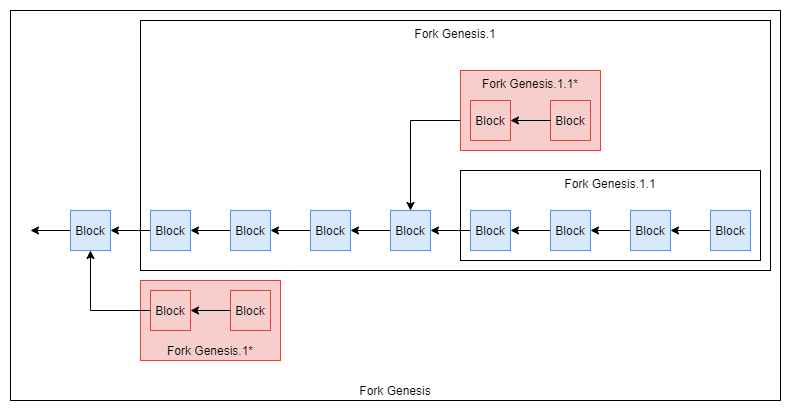
A Nakamoto blockchain is not just a sequence of messages containing state changes, but it is also a voting mechanism where each block votes for a specific fork.

This little shift of perspectives leads to a really important observation:
Each reference in Satoshis blockchain votes on a potentially unbounded number of forks with a small and constant sized hash which makes the messaging complexity completely constant and independent from factors like e.g. the size of the network.
This form of virtual voting — where nodes express their opinion through a reference in a replicated data structure instead of exchanging additional messages — is so efficient, that even projects that no longer use Satoshis consensus are still using these principles to inform the rest of the network about state changes and it is very unlikely that we will ever find a more efficient way to compress opinions.
Note: Giving the hashes that connect the messages a meaning and nodes a way to understand this meaning was the second biggest revolution of Satoshi Nakamoto.
Virtual Voting
Since our ledger model could potentially create a large amount of conflicts and voting is usually an expensive operation, we decide to copy Satoshis ideas and turn each message into a vote.
To be able to make our messages vote on the branches of our quadruple entry accounting ledger, we first need to project the information from the ledger to the tangle and then give our references a meaning.
Accordingly, we make the following adjustments to our protocol:
- A node that issues a message containing a transaction, votes for the branch that this transaction belongs to.
- The references between the messages mean approval, so that each message recursively votes for the branches of the messages it directly or indirectly references (the votes are inherited along the edges in the tangle).
- A message that votes for two pairwise conflicting branches is considered to be invalid.
The branches that a message is voting for are determined by concatenating the branches of its parents and its contained transaction.
Example
The easiest way to understand how all of this works is by looking at an example.
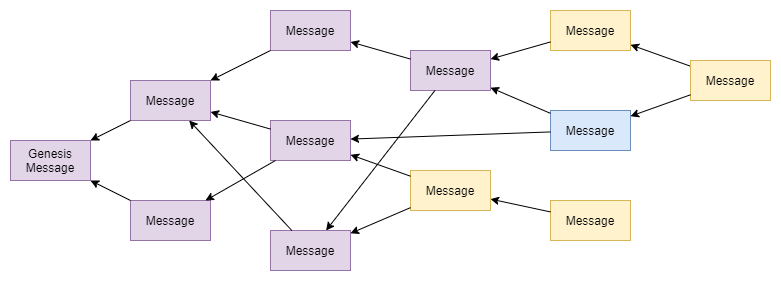
Let’s assume we have a tangle without conflicts, where all messages contain honest transactions and accordingly vote for the master branch of our quadruple entry accounting ledger.
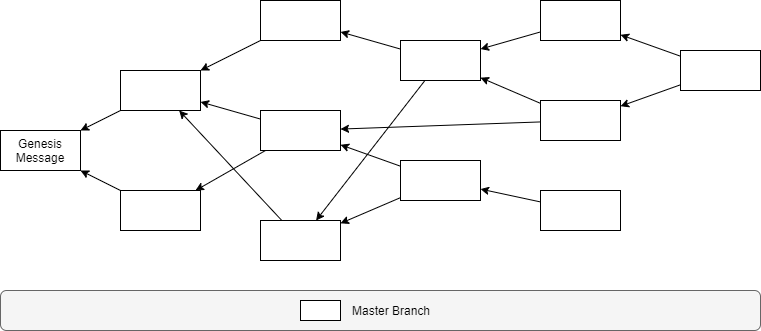
Now let’s assume, that an attacker issues a double spend — a message containing a transaction that is conflicting with one of the other messages that have been issued before.
What happens now, is that both of the conflicting transactions will be booked into their corresponding branch and these newly introduced branches will automatically propagate to the messages in the tangle according to the rules we just defined.
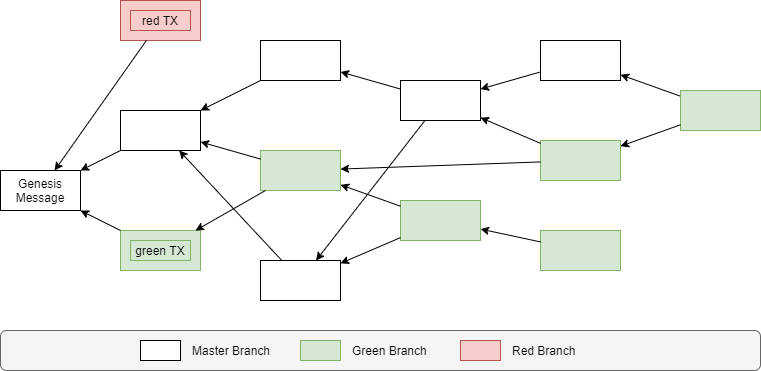
All messages in the future cone of a conflicting message, vote for the corresponding branch to be accepted by the network.
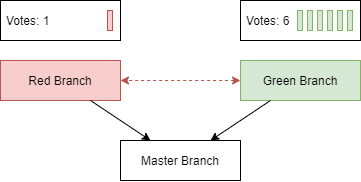
The consensus rule is very simple: The branch, that has received most approval, wins. If there is a tie, then nodes will choose the branch with the lower hash.
Similar to a blockchain, where later blocks reinforce earlier decisions by attaching to the winning chain, nodes in our protocol also continue to reference messages of the winning branch — making it harder and harder to revert decisions.
In contrast to a blockchain, that only publishes a single validator statement with each block, nodes in IOTA constantly share their opinion with each issued transaction.
This solves one of the biggest problems of Satoshis original blockchain design as it allows the network to operate in an asynchronous network model and collect a large amount of confirmations in parallel to reach finality as fast as possible.
In fact, the more transactions there are, the more votes we are able to collect and the faster we reach finality — the network gets faster with more users.
Decentralized identities
So far, our protocol is very generic and makes no assumptions about the used sybil protection, but since we want to build an identity based consensus mechanism, where different nodes have a weighted influence in the consensus process, we need to make another adjustment to our protocol.
To be able to associate each message with the weight of its issuer, we make each node sign their messages.

This way, each message can objectively be associated to a specific issuer with a certain influence in the consensus process.
Note: In times of low adoption, the most influential nodes will issue empty messages in regular intervals to secure the network.
Message payloads & layers
To enable data-centric use cases, we allow messages to not only carry transactions but arbitrary data payloads.

The first bytes of each payload encode its type which can be used to dynamically change the way it is parsed and translated into its in-memory representation.
In the same way as TCP/IP allows to define additional protocols on top of its generic data segment, this allows us to create higher level protocols.
Note: Non-transaction payloads will always be associated to the master branch as they have no inherent and shared concept of conflicts on layer1.
Decentralized applications and virtual machines
Nodes can install plugins that define a payload specific virtual machine that parses and processes the different payload types to create a decentralized application which replicates its state among all other nodes that have the same plugin installed.
Plugins use an event driven architecture to listen for messages containing the corresponding payload types.
Since any DLT uses messages that are replicated between nodes to reach consensus, it is even possible to run additional DLTs with use case specific consensus algorithms inside these virtual machines.
Nodes can individually decide which payloads to process but to achieve a good level of decentralization the decentralized application needs to have a reasonable amount of participants.
Messages that contain payloads that a node is not interested in are still gossiped but require very little computing overhead as they are handled as generic data fragments.
Note: We provide a proof of concept for a decentralized and censorship resistant chat application in the GitHub repository.
Parent types
Since even a virtual voting mechanism is still a voting mechanism where the outcome is not clear upfront, it can and will happen that honest nodes attach their messages to a part of the DAG that turns out to not be the winning one and the payloads of these messages would have to later be reattached.
This creates a game theoretic problem where nodes would instead be incentivized to attach their messages to older messages that have already been decided.
If all nodes would be rational and would modify their tip selection accordingly, we would not be able to make any progress in the voting as no new messages would arrive that would approve the conflicts and drive the system to a conclusion.
The reason why honest messages containing valid payloads can not be approved if they are referencing the wrong part of the DAG is because approval always addresses the whole past cone of a message and a message approving two double spends is considered to be invalid.
To solve this problem we introduce different types of parent references that mean different things:
- Strong parent: Votes for the referenced message and everything in its past cone.
- Weak parent: Votes for the referenced message and nothing in its past cone.
- Like parent: Votes for the referenced message and everything in its past cone (and if there are conflicting branches in the other parent, then the ones specified in this parent will prevail).
These new reference types now allow nodes to reference other honest messages independently of their references.
Conclusion
We have provided the high level specification for a new base layer voting protocol that is purely based on Satoshis Nakamotos ideas and that allows nodes to process transactions completely asynchronously and in real time.
The resulting protocol is not just conceptually very simple, but also has some other desirable properties:
- The protocol is scalable (supports an unlimited amount of nodes and validators).
- The protocol is robust (it continues to function even if validators suddenly disappear — the only thing we need in order to make decisions is a relative perception of weight).
- The protocol is fast (confirmation times are near real time).
- The protocol is secure (resilient against byzantine attackers).
- The protocol provides crash fault tolerance (nodes that are malfunctioning have a way to catch up)
- The protocol provides immutability (since messages are linked together through hashes, past decisions can not be changed if we assume that the nodes can agree on the correct set of tips).
- The protocol is efficient (it has no unnecessary overhead anywhere in the protocol — it doesn’t even send votes).
- The protocol is maximally censorship resistant (no entity controls write access to the ledger — not even a miner).
- The protocol is flexible (compatible with any kind of sybil protection — e.g. PoW, PoS, dPoS, VDFs, permissioned committees and so on).
While the concepts are very simple from a conceptual point of view, it is still a huge engineering challenge as you have many interdependent layers and levels that have to all work hand in hand.
We had to invent several new data structures and index types that allow us to efficiently manage all of this and run in more-or-less O(1) and we are still optimizing parts of the code base.
I believe that it is reasonable to assume, that the concepts introduced here form the simplest and most efficient voting protocol you could possibly ever build. It is very unlikely that we will ever get better than just adding two hashes to each transaction (I would really be surprised if you could do it with a single one).
But the most efficient voting mechanism is not the most efficient consensus mechanism, yet and we will continue to improve and extend our protocol in the upcoming parts of this series.
ELI5
We have designed a protocol that allows nodes to directly write to a distributed ledger, without any middle men and simply by sharing transactions with their neighbors.
Each transaction carries a small sticker of a few bytes and nodes can reach consensus simply by looking at the stickers and without having to exchange additional messages.
The protocol is equally robust and secure as Satoshis blockchain and will continue to function even if a very large amount of nodes are taken offline.
